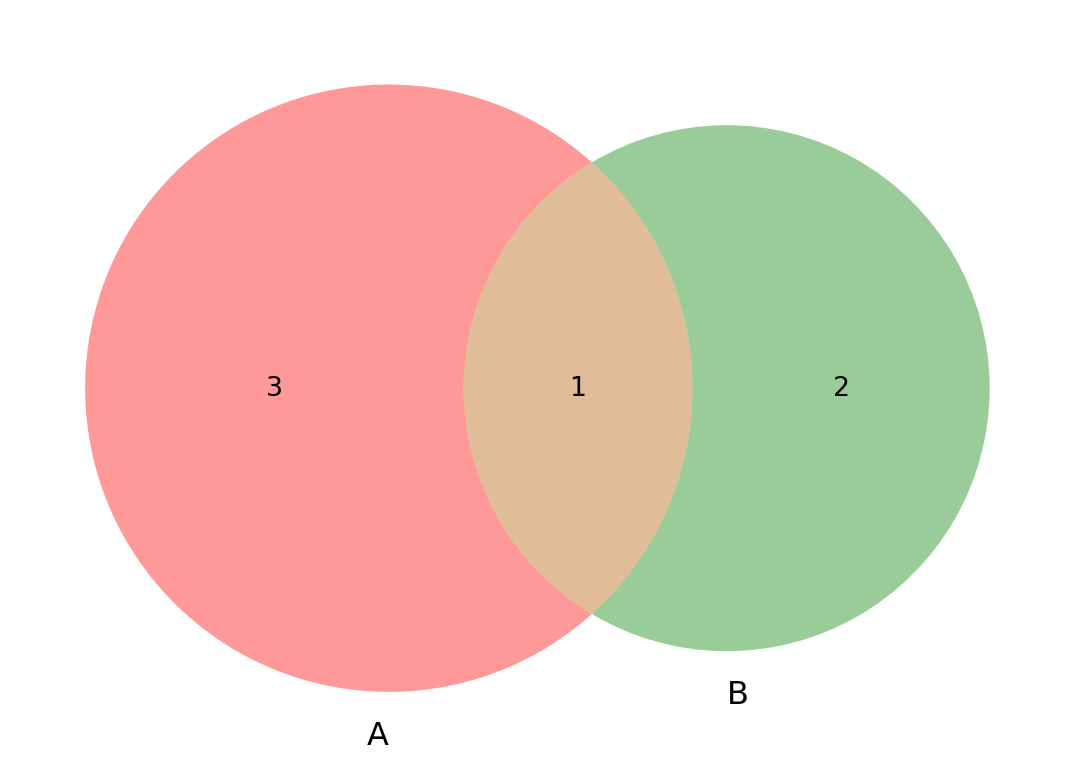
venn2([
set(['1', '2', '3', '4']),
set(['2', '5', '6'])
],
set_labels=["A", "B"]
)
Open in Google Colab: ![]()
Let us start with the definition of probability. We will return to it later in much more detail.
Definition 3.1 (Probability) A probability law is a function that assigns a number between 0 and 1 to each (measurable) event in the sample space. Let \Omega be a non-empty set and let A and B be subsets of \Omega. A probability law must satisfy the following properties:
In the following, we will discuss the key terms in the definition of probability.
As you can see the definition of probability heavily relies on the concept of sets. A set is a collection of distinct objects, considered as an object in its own right. We will use capital letters to denote sets, and the elements of a set will be denoted by lowercase letters.
There are a couple of important set operations that we will use in the context of probability:
Definition 3.2 (The Empty Set) The empty set is a special set that contains no elements. It is denoted by \emptyset or \{\}.
Definition 3.3 (Disjoint sets) Two sets are called disjoint if their intersection is the empty set, i.e. A \cap B = \emptyset. This means that the sets do not have any elements in common.
The union and intersection of sets are commutative and distributive. Commutative means that you can change the order of the sets without changing the result.
Distributive means that you can distribute the union or intersection over the other set.
Theorem 3.1 (De Morgan’s Laws) De Morgan’s laws are a pair of rules that relate the complement of the union and the intersection of sets.
This also generalizes to more than two sets.
Let A_1, A_2, \ldots, A_n be a collection of sets.
\left(\bigcup_{i=1}^n A_i\right)^c = \bigcap_{i=1}^n A_i^c .
\left(\bigcap_{i=1}^n A_i\right)^c = \bigcup_{i=1}^n A_i^c .
In the case of only three sets A_1, A_2, and A_3, the laws can be written as:
venn2([
set(['1', '2', '3', '4']),
set(['2', '5', '6'])
],
set_labels=["A", "B"]
)venn2([
set(['1', '2', '3', '4']),
set(['5', '6', '7'])
],
set_labels=["C", "D"]
)
Exercise 3.1 (De Morgan’s Laws) Use the sets from the Venn diagram in Figure 3.1 to show the validity of De Morgan’s laws. Assume that \Omega = A \cup B
The first set is A = \{1, 2, 3, 4\}
The second set is B = \{2, 5, 6\}
Write down the complements of A and B and the intersection of A and B.
Then, write down the union of A and B and its complement. Compare the results.
\begin{align*} \Omega & = A \cup B = \{1, 2, 3, 4, 5, 6\} \\ A^c & = \{5, 6\} \\ B^c & = \{1, 3, 4\} \\ A^c \cup B^c & = \{1, 3, 4, 5, 6\} \\ A \cap B & = \{2\} \\ (A \cap B)^{c} & = \{1, 3, 4, 5, 6\} = A^c \cup B^c \end{align*}
The definition of probability appears simple, but we will see that we can derive surprisingly many properties from it.
The probability of the union of two events is the sum of the probabilities of the events minus the probability of their intersection.
Theorem 3.2 (Probability of the Union of Two Events) P(A \cup B) = P(A) + P(B) - P(A \cap B)
Theorem 3.3 (Probability of the Complement) The probability of an event is one minus the probability of the complement of the event.
P(A) = 1 - P(A^c)
Proof. This follows directly from the definition of probability and the fact that A \cap A^c = \emptyset and A \cup A^c = \Omega.
P(A \cup A^c) = P(\Omega) = 1 \implies P(A) + P(A^c) = 1
For a justification of this formula, consider the Venn diagram in Figure 3.1. The probability of the union of the two events is the sum of the probabilities of the two events. However, the intersection of the two events is counted twice, so we need to subtract it once.
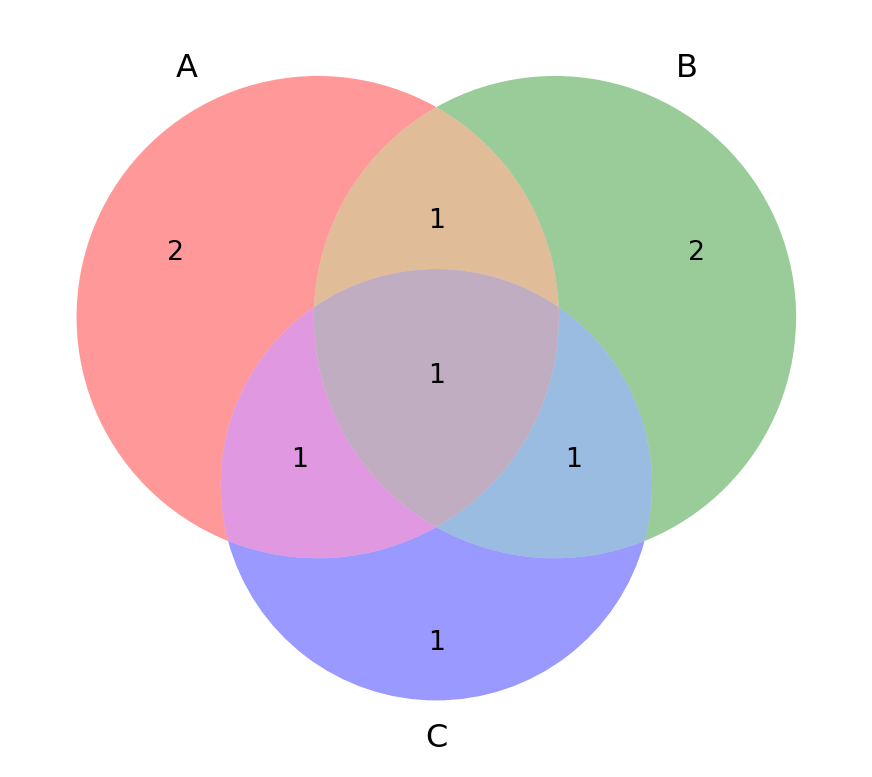
Use the following Venn diagram to show the validity of the formula.
P(A \cup B \cup C) = P(A) + P(A^c \cap B) + P(A^c \cap B^c \cap C)
venn3((
set(['1', '2', '3', '4', '9']),
set(['3', '5', '6', '7', '9']),
set(['2', '3', '5', '8'])),
set_labels=["A", "B", "C"]
)
Exercise 3.2 A consumer survey indicates that 60 percent of the customers will buy product A, 70 percent will buy product B, and 40 percent will buy both products.
Let A be the event that a customer buys product A and B be the event that a customer buys product B. We are given that P(A) = 0.6, P(B) = 0.7, and P(A \cap B) = 0.4. We want to find P((A \cup B)^c). The union of A and B is the event that a customer buys either product A or product B or both. The complement of this event is the event that a customer buys neither product A nor product B, which is what we are looking for.
We know that the probability of the complement of any event is one minus the probability of the event. Therefore, we have
P((A \cup B)^c) = 1 - P(A \cup B)
Furthermore, we already know how to compute the probability of the union of two events: it is sum of the probabilities of the two events minus the probability of their intersection.
P((A \cup B)^c) = 1 - (P(A) + P(B) - P(A \cap B))
The last formula involves only quantities that we know, so we can plug in the numbers and compute the result.
P((A \cup B)^c) = 1 - (0.6 + 0.7 - 0.4) = 0.3
For the second part, note that the event that a customer buys exactly one of the products is the event that a customer buys either product A or product B but not both. In a Venn diagram, this corresponds to the area that is in either A or B but not in A \cap B (i.e. the intersection of A and B).
This means that we need to compute P(A \cup B) - P(A \cap B) and we know P(A), P(B), and P(A \cap B).
P(A \cup B) - P(A \cap B) = P(A) + P(B) - P(A \cap B) - P(A \cap B) = P(A) + P(B) - 2P(A \cap B)
Consider a couple of simple experiments with a random outcome
The sample space of the experiment is the set of all possible outcomes. For the coin flip, the sample space is \{H, T\}, and for the die roll, the sample space is \{1, 2, 3, 4, 5, 6\}. These are very easy examples, but depending on the experiment, the sample space can be much more complex.
There are no formulas that tell how to construct a sample space for a given experiment. However, there are two key properties that the sample space must satisfy:
An event is a subset of the sample space. For example, if you are flipping a coin, the event of getting heads is the subset \{H\} of the sample space \{H, T\}. If you are rolling a die, the event of getting an even number is the subset \{2, 4, 6\} of the sample space \{1, 2, 3, 4, 5, 6\}.
In experiments with a finite number of equally likely outcomes, the probability of an event is the number of outcomes in the event divided by the total number of outcomes in the sample space. For example, the probability of getting heads when flipping a coin is 1/2 because there is one outcome in the event \{H\} and two outcomes in the sample space \{H, T\}. The probability of getting an even number when rolling a die is 3/6 = 1/2 because there are three outcomes in the event \{2, 4, 6\} and six outcomes in the sample space \{1, 2, 3, 4, 5, 6\}.
P(A) = \frac{\text{number of elements in } A}{\text{number of elements in the sample space}}
A sample space is discrete if it consists of a finite or countably infinite number of outcomes. For example, the sample space of rolling a die is discrete because there are only six possible outcomes. The sample space of flipping a coin is also discrete because there are only two possible outcomes. The number of accidents in a day is also a discrete sample space because it can only take on integer values (which are countably infinite). The sample space of selecting a real number between 0 and 1 (or any other real interval) is not discrete because there are uncountably many possible outcomes (Cantor’s theorem).
Exercise 3.3 (The Sample Space of Three Coin Flips) Consider an experiment of flipping a coin three times (each toss can result either in a head (H) or in a tail (T) ).
The size of the sample space is 2^3 = 8. The sample space is \{HHH, HHT, HTH, HTT, THH, THT, TTH, TTT\}.
The probability of the event A is 4/8 = 1/2 and the probability of the event B is 4/8 = 1/2.
# A coin flipping game
# Here we simulate the result of 3 coin flips repeated 10 times (1 for heads, 0 for tails)
# np.random.choice selects a value at random from the given list
# The size specifies the number of times the selection is made
# In our case, we are selecting 3 values 10 times and storing the results in coin_results
coin_3flips = np.random.choice([1, 0], size=[10, 3])
coin_3flipsarray([[0, 1, 0],
[0, 1, 1],
[1, 1, 1],
[0, 1, 1],
[1, 0, 0],
[0, 0, 1],
[1, 0, 1],
[0, 0, 1],
[0, 0, 0],
[0, 1, 0]])# Check the shape of the coin_results array, it should be (10, 3), the same as the size we specified
coin_3flips.shape(10, 3)# The _number_ of games where the first coin landed on heads (1) in each of the 10 games
# - We select the first column of the matrix (coin_results[:, 0]), because the first coin flip is stored in the first column
# - We then check how many times the value 1 appears in the first column
# - The sum() function is used to count the number of times the value 1 appears in the first column
(coin_3flips[:, 0] == 1).sum()3# The _proportion_ of games where the number of heads in each game is even
(coin_3flips.sum(axis=1) % 2 == 0).mean()0.4Exercise 3.4 (The Sample Space of Two Die Rolls) Consider an experiment of rolling a four sided die twice.

Assume that the die is fair and that all outcomes are equally likely. - What are the probability of the events A and B: P(A) and P(B)? - What is the probability of the event A \cap B? - What is the probability of the event A \cup B? - What is the probability of the event A^c? - What is the probability of the event A \cap C?
The size of the sample space is 4^2 = 16. The sample space is
\Omega = \left\{ \begin{array}{cccc} (1, 1), (2, 1), (3, 1), (4, 1), \\ (1, 2), (2, 2), (3, 2), (4, 2), \\ (1, 3), (2, 3), (3, 3), (4, 3), \\ (1, 4), (2, 4), (3, 4), (4, 4) \end{array} \right\}
The event A consists of the outcomes \{(3, 4), (4, 3)\}. It has two elements, so assuming that each sequence in the sample space is equally likely, the probability of A is 2/16 = 1/8.
The event B consists of the outcomes \{(1, 2), (2, 1), (4, 1), (1, 4), (3, 4), (4, 3)\}. It has six elements, so the probability of B is 6/16 = 3/8.
The event C consists of the outcomes \{(2, 1), (3, 1), (4, 1), (3, 2), (4, 2), (4, 3)\}. It has six elements, so the probability of C is 6/16 = 3/8.
The event A \cap B consists of the outcomes \{(3, 4), (4, 3)\}, so the probability of A \cap B is 2/16 = 1/8. It is the same as the probability of A because a is a subset of B (A \subset B).
The event A^c consists of \Omega \ A. Its probability is P(A^c) = 1 - P(A) = 7/8. The event A \cap C consists of only one outcome \{(3, 4)\} (which is common to A and C), so the probability of A \cap C is 1/16.
# Simulation of 10 rolls of a four-sided die
die_rolls = np.random.choice([1, 2, 3, 4], size=[10, 2])
die_rollsarray([[2, 1],
[2, 2],
[4, 2],
[1, 1],
[4, 2],
[1, 1],
[2, 3],
[3, 4],
[1, 1],
[4, 3]])# Event A: sum of the two rolls is greater than 7
# - we can sum the values in each row to get the total of the two rolls: this is what die_rolls.sum(axis=1). The axes in the arrays are indexed: 0 for rows and 1 for columns
# - The == operator checks if the sum is equal to 7 and returns a boolean array (True and False)
event_A = (die_rolls.sum(axis=1) == 7)
event_Aarray([False, False, False, False, False, False, False, True, False,
True])# Event B: sum of the two rolls is odd (the != operator checks for inequality)
# - as in the previous cell, we sum the values in each row to get the total of the two rolls
# - % is the modulo operator. If the sum is even, the modulo of 2 will be 0, and if it is odd, the modulo will be 1
# - the != operator checks if the modulo is different from zero and returns a boolean array (True and False)
event_B = (die_rolls.sum(axis=1) % 2 != 0)
event_Barray([ True, False, False, False, False, False, True, True, False,
True])# Event C: first roll is greater than the second roll.
# - the square brackets after the array are used to select parts of the array. The : operator selects all the elements in the array (in this case, all the rows)
# - after a comma we can specify the column we want to select. The first column has index 0 and the second column has index 1
# - the > operator checks if the value in the first column is greater than the value in the second column and returns a boolean array (True and False)
event_C = (die_rolls[:, 0] > die_rolls[:, 1])
event_Carray([ True, False, True, False, True, False, False, False, False,
True])# Event D: $D$ the two rolls are the same.
# Exactly as before, but here we check for equality using the == operator
event_D = (die_rolls[:, 0] == die_rolls[:, 1])
event_Darray([False, True, False, True, False, True, False, False, True,
False])# The intersection of A and B (A and B occurring together)
# - The & operator is used to combine two boolean arrays. It returns a new boolean array where the value is True only if both arrays have True in the same position
event_A_and_B = event_A & event_B
event_A_and_B.sum()2Exercise 3.5 (Racing Cars and Betting) Consider a car race with 6 cars. You believe that the probability of winning is equal for the first three cars, and the probabilities of winning for cars 4, 5, and 6 are equal to 1/7. You must place a bet on one of the following two events:
Which event would you bet on? Justify your answer. The reward is the same for both events.
Let A_1, A_2, A_3, A_4, A_5, A_6 be the events that cars 1, 2, 3, 4, 5, and 6 win, respectively. Only one car can be the winner, so these events cannot occur simultaneously (they are disjoint). We want to calculate the probability of the events
A_1 \cup A_2 \cup A_5 \quad \text{and} \quad A_3 \cup A_5 \cup A_6
As the events are disjoint, the probability of their union is the sum of the probabilities of the events. We have
P(A_1 \cup A_2 \cup A_5) = P(A_1) + P(A_2) + P(A_5) \\ P(A_3 \cup A_5 \cup A_6) = P(A_3) + P(A_5) + P(A_6)
We know the probabilities for the events A_4, A_5, A_6:
P(A_4) = P(A_5) = P(A_6) = 1/7
We are still missing the probabilities for the events A_1, A_2, A_3 but we can obtain them from the fact that the sum of the probabilities of all elements of the sample space must be 1.
\begin{align*} \Omega = A_1 \cup A_2 \cup A_3 \cup A_4 \cup A_5 \cup A_6 \implies \\ P(A_1) + P(A_2) + P(A_3) + P(A_4) + P(A_5) + P(A_6) = 1 \\ P(A_1) + P(A_2) + P(A_3) + 3 \cdot 1/7 = 1 \end{align*}
We know that the first three probabilities are equal, so we can write
3x + 3 \cdot 1/7 = 1 \implies x = 4/21 \implies P(A_1) = P(A_2) = P(A_3) = 4/21
Now you simply substitute these probabilities in the equations above and compare the results. As the rewards are the same, you should bet on the event with the higher probability.
Exercise 3.6 (Student Enrollment) In a class of 100 students, 36 of them are enrolled in a statistics course, 28 in microeconomics, and 18 in an macroeconomics course. Furthermore, 22 of the students study both statistics and microeconomics, 12 study both statistics and macroeconomics, 9 study both microeconomics and macroeconomics, and 4 are enrolled in all three courses. You select a student at random. What is the probability that the student is enrolled in at least one of the courses?
This exercise is about the inclusion-exclusion principle. Let St be the event that a student is enrolled in statistics, Mi be the event that a student is enrolled in microeconomics, and Ma be the event that a student is enrolled in macroeconomics. We want to calculate the probability of the event St \cup Mi \cup Ma. We have
P(St \cup Mi \cup Ma) = P(St) + P(Mi) + P(Ma) - P(St \cap Mi) - P(St \cap Ma) - P(Mi \cap Ma) + P(St \cap Mi \cap Ma)
Justify this formula by drawing a Venn diagram. The probabilities of the events St, Mi, and Ma are 36/100, 28/100, and 18/100, respectively. The probabilities of the pairwise intersections are 22/100, 12/100, and 9/100. The probability of the intersection of all three events is 4/100. Substitute these values into the formula above to get the result.
Exercise 3.7 (Dice Rolls Until 2) You take a four-sided die and roll it until you get a 2. Describe the sample space of the experiment.
Exercise 3.8 (Probability Model) You are given a loaded four-sided die. The even numbers are twice as likely as the odd numbers, but the each even number is equally likely and each odd number is equally likely. Construct a probability model for this die.
The sample space of this experience is \{1, 2, 3, 4\}. We know the following:
\begin{align*} P(\{1\}) = P(\{3\}) = x \\ P(\{2\}) = P(\{4\}) = 2x \end{align*}
As the probabilities of all outcomes must sum to 1, we have
P(\{1\}) + P(\{2\}) + P(\{3\}) + P(\{4\}) = 1 \implies 2x + 2x + x + x = 1 \implies x = 1/6
So the probability model is
\begin{align*} P(\{1\}) = P(\{3\}) = 1/6 \\ P(\{2\}) = P(\{4\}) = 1/3 \end{align*}
Exercise 3.9 (Bonferroni’s Inequalities) Let A and B be two events. Show that
P(A \cap B) \geq P(A) + P(B) - 1
Also, let A_1, A_2, \ldots, A_n be a sequence of events. Show that
P(\cap_{i=1}^n A_i) \geq \sum_{i=1}^n P(A_i) - n + 1
The first inequality follows directly from the definition of probability. We know that
P(A \cup B) = P(A) + P(B) - P(A \cap B) \leq 1
For the second part, we need to use de Morgan’s laws, specifically the second part of Theorem 3.1. We have
P(\cap_{i=1}^n A_i) = 1 - P((\cup_{i=1}^n A_i)^c) \geq 1 - \sum_{i=1}^n P(A_i^c) = 1 - \sum_{i=1}^n (1 - P(A_i)) = \sum_{i=1}^n P(A_i) - n + 1
Exercise 3.10 Let A and B be two sets. Describe the set (A \cap B^c) \cup (A^c \cap B) in words and use a Venn diagram to illustrate it. Use the Venn diagram to explain why the following formula holds:
P((A \cap B^c) \cup (A^c \cap B)) = P(A) + P(B) -2 P(A \cap B),
To describe the set (A \cap B^c) \cup (A^c \cap B) in words, we can use the customers and products example from Exercise 3.2. Let A be the event that a customer buys product A and B be the event that a customer buys product B.
The event (A \cap B^c) is the event that a customer buys product A but not product B. The event (A^c \cap B) is the event that a customer buys product B but not product A. The union of these two events is the event that a customer buys either product A or product B but not both, or in other words, the event that a customer buys exactly one of the products.