In this notebook, we will discuss hypothesis tests. To understand statistical tests, it is useful to think about how a judge in a court must make a decision about whether to convict a defendant or not. The prosecution presents a case that the defendant is guilty, the case being a summary of the evidence that the defendant committed the crime. The judge does not know wheher the defendent is guilty or not, so he/she must rely on the evidence presented by the prosecution and determine if the evidence is strong enough to convict the defendant. The judge can make to types of error:
To convict an innocent person (Type I error)
Fail to convict a guilty person (Type II error)
Reality/Decision
Convict
Fail to convict
Defendent innocent
Type I error
Correct
Defendent guilty
Correct
Type II error
In statistics we very much face the same situation as the judge. We have a research question, we collect data and we must decide whether the data appears consistent with some conjecture about the state of the world or not. The conjecture is usually called a hupothesis.
15.2 Hypothesis Testing
Let’s say that we suspect that the share of customers interested in some of our products is p \geq 0.7 and suppose that we collect a sample of 100 customers and find that 60 of them are interested. The question is: is the sample consistent with our conjecture that the share of interested customers is at least 0.7?
\begin{align*}
H_0&: p \geq 0.7 \quad \text{Null Hypothesis}\\
H_1&: p < 0.7 \quad \text{Alternative}
\end{align*}
Now we need to decide whether our observed 60 interested customers are consistent with the null hypothesis. Intuitively, if the share of interested customers is 0.7, then we would expect to see 70 interested customers in our sample of 100 customers. The question is: is 60 interested customers too far from 70 to be consistent with the null hypothesis? In other words: if the share of interested customers is 0.7, how likely is it that we would see 60 or fewer interested customers in our sample of 100 customers?
To do this, we need to summarize the data in a single number that we can use to make a decision. Fortunately, in this case the number of interested customers in our sample is already a summary of the data. Nevertheless, it is useful to write it down formally. Let X_1, X_2, \ldots, X_n are the answers of the n = 100 customers in our sample before they answer. Each X_i is a random variable that can take the value 1 if the customer is interested in our products and 0 otherwise and because our sample is random, the first customer’s answer is one with probability p = 0.7 and zero with probability 1 - p = 0.3. The same is true for the second customer and so on.
Let us look at p = 0.7 which is closest to the alternative hypothesis. We can ask the question: what is the probability to observe 60 or fewer interested customers in our sample of 100 customers if the share of interested customers is 0.7? In order to answer this question, we need to know the distribution of the random variable X = X_1 + X_2 + \ldots + X_{100}. Assuming that the answers of the customers are independent, we have that X is a binomial random variable with parameters n = 100 and p = 0.7. The probability mass function of a binomial random variable is given by
It is cumbersome to calculate this sum by hand, so we will use the computer. In Python, we can use the scipy.stats.binom module to calculate the probability mass function of a binomial random variable. The function binom.cdf calculates the cumulative distribution function of a binomial random variable. The cumulative distribution function of a random variable X is defined as F(x) = P(X \leq x) and is exactly what we need here.
from scipy import statsimport numpy as npn =100p =0.7p_hat =0.6expected_successes = p * nobserved_successes = p_hat * nprint("Probability of seeing less or equal to 60 successes out of 100 trials:", stats.binom.cdf(observed_successes, n, p))
Probability of seeing less or equal to 60 successes out of 100 trials: 0.020988576003924803
We have seen that the probability to observe 60 or fewer interested customers in our sample of 100 customers is about 0.021. This probability is called the p-value of the test and it is important to understand what it means. The number of successes (the interested customers) is a summary of the data (a statistic). When we computed the p-value using a population share of successes of 0.7, so the p-value is a conditional probability, the condition being that the null hypothesis is true. It tells you how surpirsing the data (as summarized by the statistic) is if the null hypothesis is true. This is similar to the approach in mathematics where we can prove something by assuming that some conjecture is true and then derive a contradiction. In applied statistics there is no such thing as a proof as in mathematics, but the p-value serves as a kind of probabilistic “proof”. If it is very small, then the data is surprising if the null hypothesis is true and we choose to believe the data rather than the null hypothesis. If the p-value is large, then the data is not surprising and we can say that the data is consistent with the null hypothesis. To see this, we can run a small simulation to see how the p-value behaves if the null hypothesis is true.
## Generate a sample of 1000 binomial random variables, each showing the number of successes in 100 trialssample100 = np.random.binomial(n, p, size =10000)# Print the first 20 samplesprint(sample100[0:20])print("Mean of the samples:", np.mean(sample100))# Now we can count the number of samples with less or equal to 60 successesprint("Number of samples with less or equal to 60 successes:", np.sum(sample100 <=60))
[81 71 75 77 67 72 70 74 68 70 74 72 72 77 70 68 73 73 70 68]
Mean of the samples: 69.9515
Number of samples with less or equal to 60 successes: 215
1000*0.0209885760
20.988576
As the simulation shows, if the true share of the interested customers is 0.7, then we expect to get about 21 samples out of 1000 where the number of successes is less or equal to 60. This is a rare event, so with a p-value of 0.021 we can reject the null hypothesis that the share of interested customers is at least 0.7. In other words, the data is not consistent with the null hypothesis. At this point you should be asking the question: how surprising must the data be so that we conclude that the data is inconsistent with the conjecture. This question does not have a definitive answer, but a common rule of thumb is to reject the null hypothesis if the p-value is less than 0.05. This is called the 5% significance level.
15.3 Confidence Interval for the Population Proportion
The observed proportion of successes in the last example served as an estimate for the population proportion. Indeed, we have shown that this is the maximum likelihood estimate. While the estimate is useful, it does not relate any information about the uncertainty behind it. We know that there is uncertainty, because we have calculated the estimate using a single sample and we are aware of the fact that we could have selected another sample and we could have obtained another result.
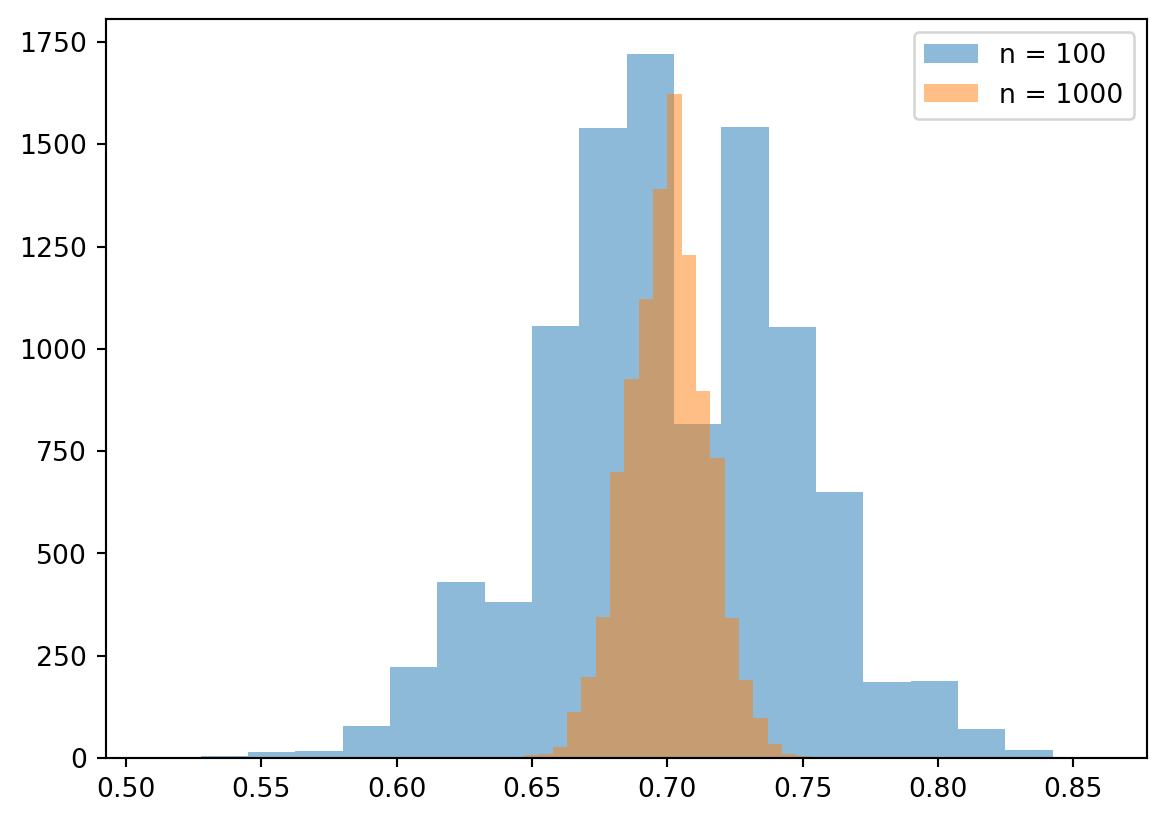
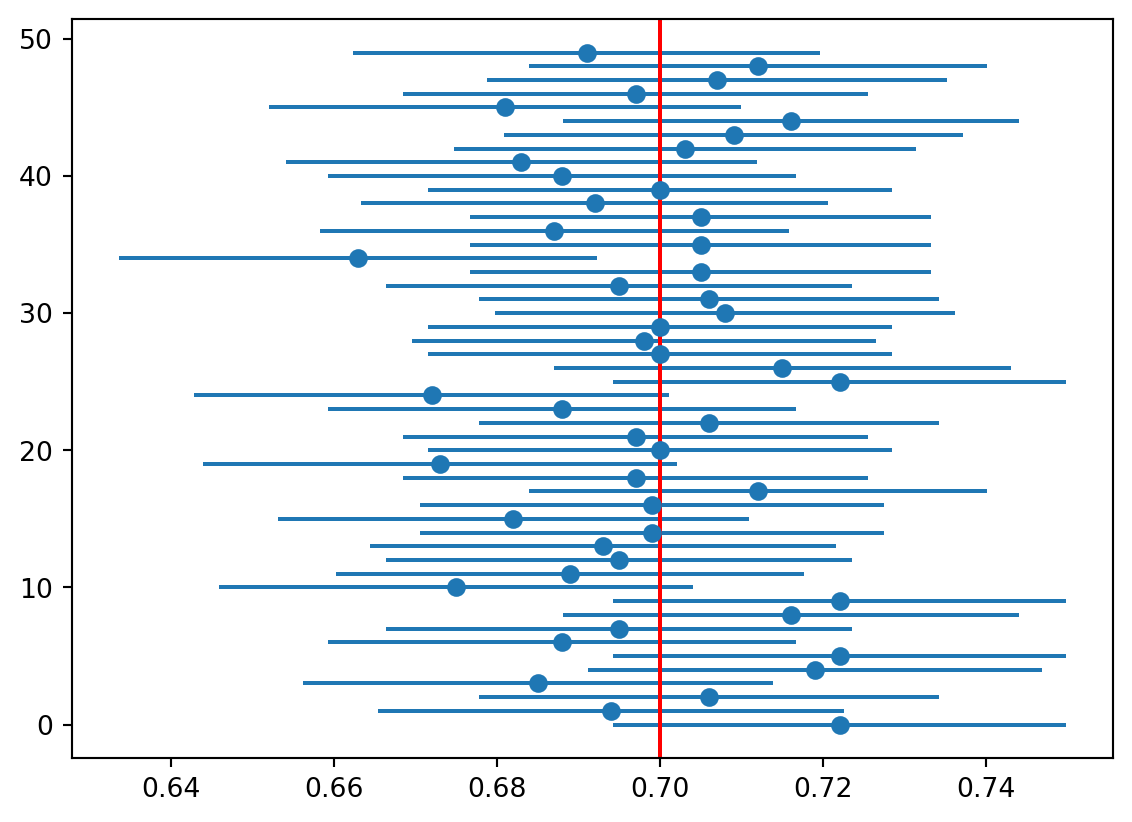
The following figure shows compares the distributions of the sample proportion over 10,000 samples for a sample size of 100 and a sample size of 1,000. All samples are drawn from a population with a share of successes of 0.7. In the figure you can see that the distribution of the sample proportion is narrower for a sample size of 1,000 compared to a sample size of 100. Intuitively, this makes sense, because the more data we have, the more we can learn about the population. The wider distribution in the case of the smaller sample size means that we are more uncertain about the population proportion, because our estimate could have been very different if we had selected another sample. In the more narrow distribution, we are more certain about the population proportion, because it does not matter that much which sample we select.
# Visualize the distribution of the samplesimport matplotlib.pyplot as pltn1000 =1000sample1000 = np.random.binomial(n1000, p, size =10000)# Create two histograms for the two samplesplt.hist(sample100 / n, bins =20, alpha =0.5, label ="n = 100")plt.hist(sample1000 / n1000, bins =20, alpha =0.5, label ="n = 1000")plt.legend(loc ="upper right")plt.show()
Using the distribution above, we can calculate a interval of plausible values for the population proportion.
# Central 95% interval for the population proportion of successes# Calculate the 0.025 and 0.975 quantiles of the distribution of the samplesq_025 = np.quantile(sample100 / n, 0.025)q_975 = np.quantile(sample100 / n, 0.975)print("Central 95% interval for the population proportion of successes:", q_025, q_975)# About 95 percent of the samples have a proportion of successes between 0.61 and 0.79np.mean((sample100 / n > q_025) & (sample100 / n < q_975))
Central 95% interval for the population proportion of successes: 0.61 0.79
0.9378
In the vast majority of practical applications, we only observe one sample and we don’t have the luxury of a simulation to see the distribution of the sample proportion. However, we can use analytical methods to approximate this distribution. One very popular method relies on the central limit theorem. The central limit theorem states that the distribution of the sample mean of a random sample of size n from a population with mean \mu and variance \sigma^2 approaches a normal distribution with mean \mu and variance \sigma^2/n as n approaches infinity. Thus, if we standardize the sample mean, we obtain a random variable that is approximately standard normally distributed.
Using this distribution we can calculate its quantiles and obtain a confidence interval for the population proportion.
# The 0.025 and 0.975 quantiles of the standard normal distributionqn_025 = stats.norm.ppf(0.025)qn_975 = stats.norm.ppf(0.975)print("0.025 and 0.975 quantiles of the standard normal distribution:", qn_025, qn_975)
0.025 and 0.975 quantiles of the standard normal distribution: -1.9599639845400545 1.959963984540054
15.4 Quantiles of the Standard Normal Distribution
The standard normal distribution is a very important in statistics for several reasons, one of which is that is emerges as the limit of the distribution of the sample mean of a random sample. In the following we need to know how to calculate quantiles of the standard normal distribution and what they mean.
For any distribution, the CDF is defined as F(x) = P(X \leq x) and the quantile function is defined as Q(p) = \inf\{x \in \mathbb{R} : F(x) \geq p\}. The quantile function is the inverse of the CDF. The CDF answers the question: what is the probability that the random variable is less than or equal to some fixed value x. The quantile function answers the question: what is the value x such that the probability that the random variable is less than or equal to x is at least p.
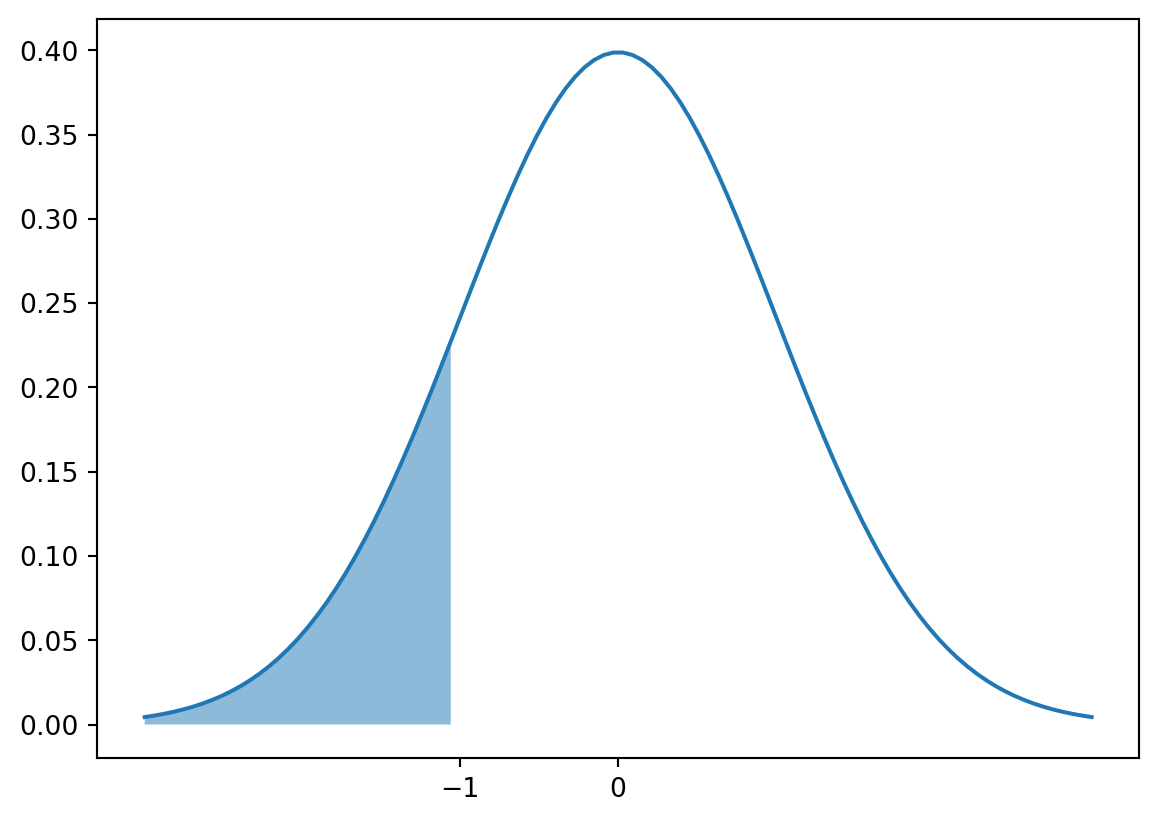
# Plot the standard normal distribution and the probability of events less than -1x = np.linspace(-3, 3, 100)y = stats.norm.pdf(x)plt.plot(x, y)plt.fill_between(x, y, where = x <-1, alpha =0.5)plt.xticks([-1, 0])plt.show()
# Calculate the probability of observing less than -1 from a standard normal distributionprint("Probability of observing less than -1 from a standard normal distribution:", stats.norm.cdf(-1))
Probability of observing less than -1 from a standard normal distribution: 0.15865525393145707
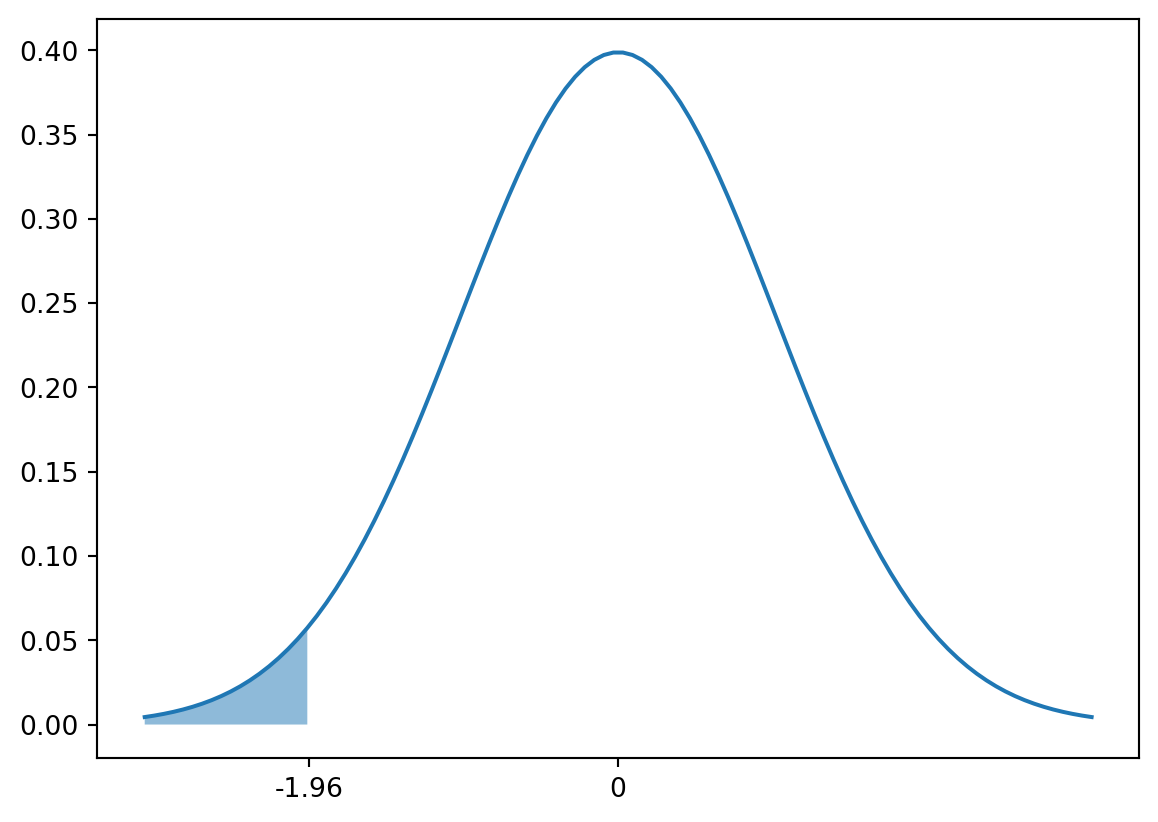
Now we can invert the question. What is the fixed value x such that the probability that the random variable is less than or equal to x is at least 0.025? This is the 0.025 quantile of the standard normal distribution. We can compute it using the scipy.stats.norm module in Python. The function norm.ppf (percent point function ) calculates the quantile function of the standard normal distribution. The 0.025 quantile of the standard normal distribution is about -1.96. This means that the probability that a standard normally distributed random variable is less than or equal to -1.96 is about 0.025.
print("The 0.025 quantile of the standard normal distribution", stats.norm.ppf(0.025))print("The probability of observing less than the 0.025 quantile of a standard normal distribution", stats.norm.cdf(stats.norm.ppf(0.025)))
The 0.025 quantile of the standard normal distribution -1.9599639845400545
The probability of observing less than the 0.025 quantile of a standard normal distribution 0.024999999999999977
# Plot the normal distribution and the probability of events less than the 0.025 quantilex = np.linspace(-3, 3, 100)y = stats.norm.pdf(x)plt.plot(x, y)plt.fill_between(x, y, where = x < stats.norm.ppf(0.025), alpha =0.5)plt.xticks([stats.norm.ppf(0.025), 0], [stats.norm.ppf(0.025).round(2), 0])
([<matplotlib.axis.XTick at 0x7fea4db3e2d0>,
<matplotlib.axis.XTick at 0x7fea4db3e2a0>],
[Text(-1.9599639845400545, 0, '-1.96'), Text(0.0, 0, '0')])
We can also calculate the 0.975 quantile of the standard normal distribution. This quantile is about 1.96.
# Calculate the probability of observing less than the 0.975 quantile from a standard normal distributionprint("The 0.975 quantile of the standard normal distribution", stats.norm.ppf(0.975))print("Probability of observing less than the 0.975 quantile from a standard normal distribution:", stats.norm.cdf(stats.norm.ppf(0.975)))
The 0.975 quantile of the standard normal distribution 1.959963984540054
Probability of observing less than the 0.975 quantile from a standard normal distribution: 0.975
# Plot the normal distribution and the probability of events less than the 0.975 quantilex = np.linspace(-3, 3, 100)y = stats.norm.pdf(x)plt.plot(x, y)plt.fill_between(x, y, where = x < stats.norm.ppf(0.975), alpha =0.5)plt.xticks([0, stats.norm.ppf(0.975)], [0, stats.norm.ppf(0.975).round(2)])plt.show()
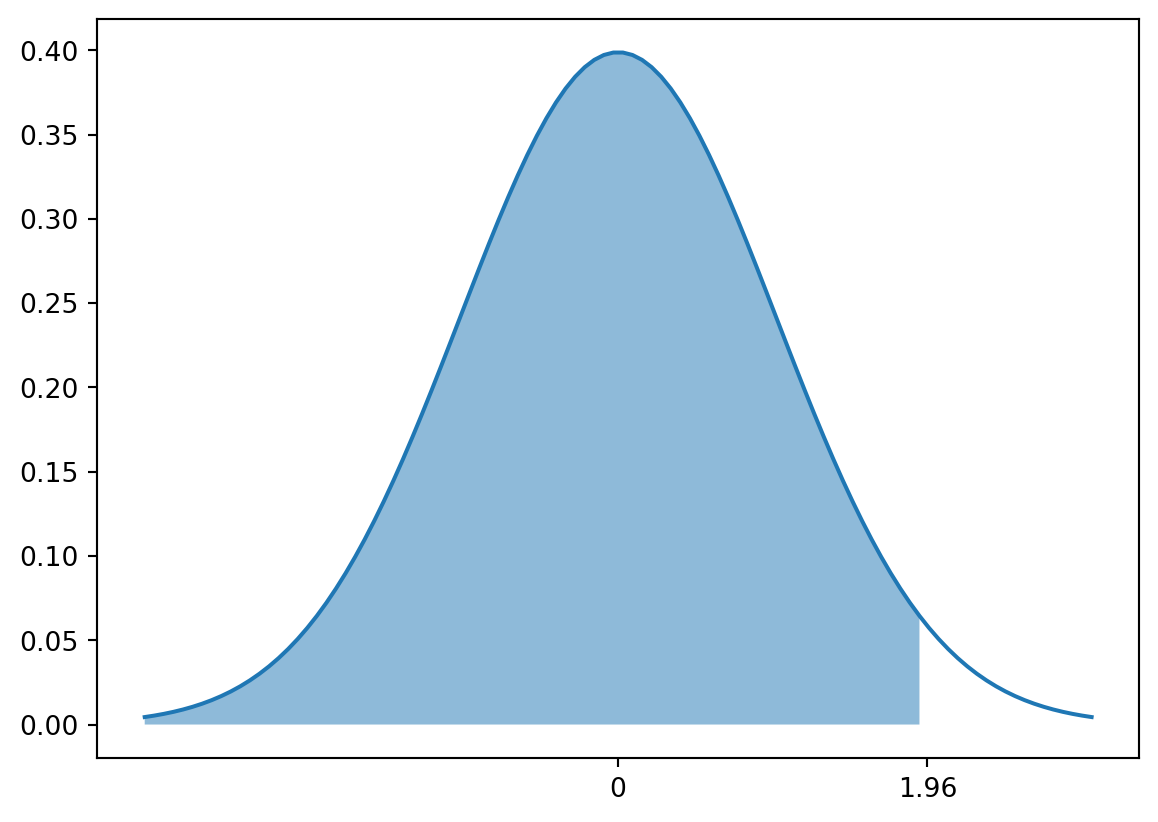
Both of these quantiles are useful, because we know that the probability of events between them is equal to 0.95, i.e. there is a 5 percent chance to observe a value outside of this interval.
# Plot the normal distribution and the probability of events between the 0.025 and 0.975 quantiles# Set the axis breaks to the quantilesx = np.linspace(-3, 3, 100)y = stats.norm.pdf(x)plt.plot(x, y)plt.fill_between(x, y, where = (x > stats.norm.ppf(0.025)) & (x < stats.norm.ppf(0.975)), alpha =0.5)plt.xticks([stats.norm.ppf(0.025), stats.norm.ppf(0.975)], [stats.norm.ppf(0.025).round(2), stats.norm.ppf(0.975).round(2)])
([<matplotlib.axis.XTick at 0x7fea4da20470>,
<matplotlib.axis.XTick at 0x7fea4da20440>],
[Text(-1.9599639845400545, 0, '-1.96'), Text(1.959963984540054, 0, '1.96')])
We known that 95 percent of the probability of a distribution is between its 0.025 and 0.975 quantiles, so
Because the population proportion is unknown, we replace it with the sample proportion in the calculation of the standard error and we obtain a confidence interval for the population proportion.
In our example, we have observed 60 interested customers in a sample of 100 customers. The sample proportion is \hat{p} = 0.6 and the confidence interval is
In order to avoid misinterpretation, notice that it does not make sense to ask the question: what is the probability of the population proportion being in the interval (0.51, 0.69). Because we view the population proportion as a fixed value it is either within that interval or outside of it. The coverage probability makes sense only in the context of repeated sampling, because the bounds of the interval are random and they depend on the sample we have drawn. So when interpreting the confidence interval, you should view it as a range of plausible values for the population parameter (the proportion in this case), because it was obtained from a procedure that has a 95% chance of producing an interval that contains the population parameter.
The simulation below illustrates this point.
print("Lower CI bound", 0.6-1.96* np.sqrt(0.6*0.4/100))print("Upper CI bound", 0.6+1.96* np.sqrt(0.6*0.4/100))
Lower CI bound 0.5039800020828994
Upper CI bound 0.6960199979171006
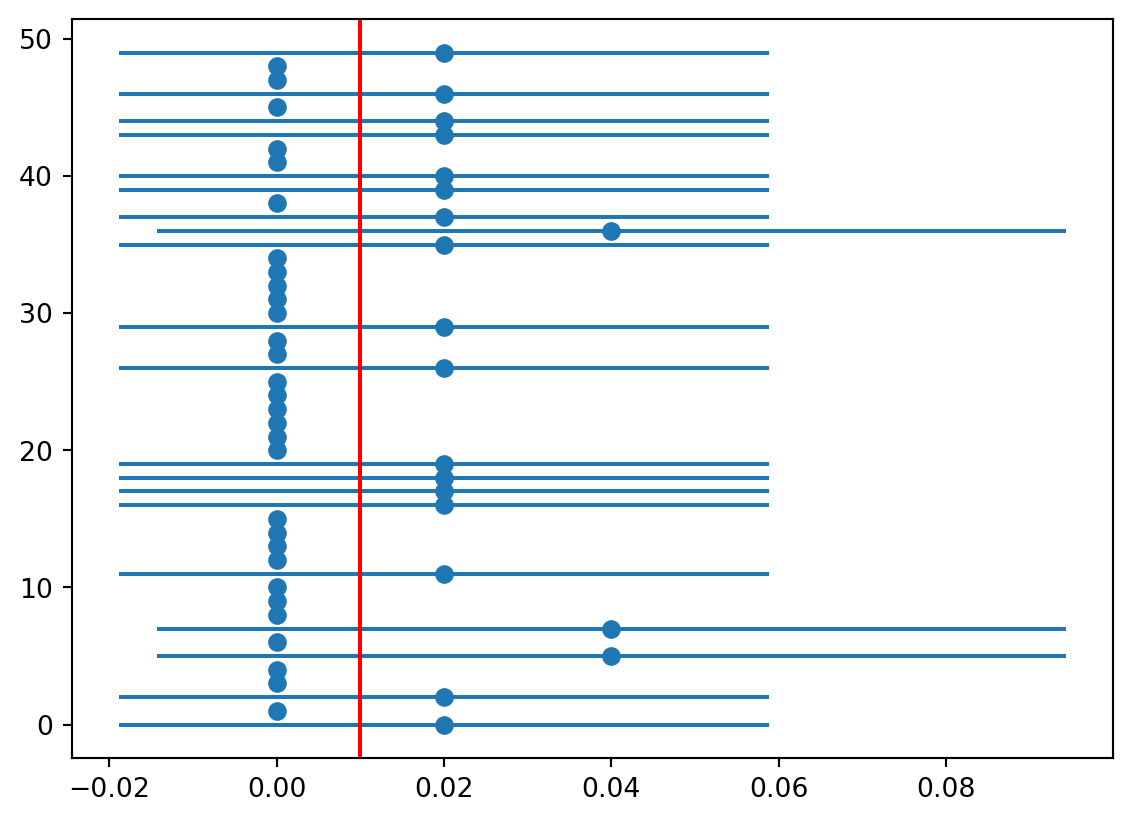
# Compute the confidence intervals for the population proportion of successesp_hat = sample1000 / n1000se = np.sqrt(p_hat * (1- p_hat) / n1000)print("Standard error of the sample proportion of successes:", se)ci_025 = p_hat - qn_975 * seci_975 = p_hat - qn_025 * se# Plot the confidence intervals# Plot the confidence intervals and the population proportion of successes for the first 50 samples# with the sample number on the y-axisshow_samples =50plt.errorbar(p_hat[0:show_samples], range(show_samples), xerr = qn_975 * se[0:show_samples], fmt ="o")plt.axvline(p, color ="red")plt.show()
Standard error of the sample proportion of successes: [0.01416743 0.01457271 0.01440708 ... 0.01463827 0.0144496 0.01427498]
print("Number of confidence intervals that contain the population proportion of successes:", np.sum((ci_025 < p) & (ci_975 > p)))print("Proportion of confidence intervals that contain the population proportion of successes:", np.mean((ci_025 < p) & (ci_975 > p)))
Number of confidence intervals that contain the population proportion of successes: 9481
Proportion of confidence intervals that contain the population proportion of successes: 0.9481
16 Comparing the Simulated Distribution and the Normal Approximation
We derived the limits of the confidence intervals using the central limit theorem. Here we want to compare the simulated distribution of the sample proportion with the normal approximation.
# Plot the quantile
16.1 Comparing Two Proportions (Optional)
In the last example, we have compared the sample proportion to a fixed value. In many practical applications, we are interested in comparing two proportions. For example, we might be interested to compare the propensity to buy a product between two groups of customers (e.g. male/female, young/old, etc.). In this case, we have two samples and we want to know if the difference in the sample proportions is consistent with zero. Let the population proportions of the success in the two groups be p_1 and p_2 and let \hat{p}_1 and \hat{p}_2 be the sample proportions. The null hypothesis is that the two population proportions are equal and the alternative hypothesis is that they are not equal.
The test statistic is the difference in the sample proportions
\begin{align*}
\hat{p}_1 - \hat{p}_2
\end{align*}
Under the null hypothesis, the two sample proportions are equal to the same population proportion p. The variance of the difference in the sample proportions is
We can estimate the common population proportion p using the pooled sample proportion. Previously, we have tested a hypothesis against a one-sided alternative. In the present case, we are testing against a two-sided alternative, because both large positive values of the difference in the sample proportions and large negative values are evidence against the null hypothesis. The p-value is calculated as
p1 =0.5p2 =0.7n =100sample1 = np.random.binomial(n, p1, size =1)sample2 = np.random.binomial(n, p2, size =1)# Perform a z-test for the difference of two population proportionsp_hat1 = sample1 / np_hat2 = sample2 / npooled_sample = sample1 + sample2pooled_n =2* np_hat_pooled = pooled_sample / pooled_nse_pooled = np.sqrt(p_hat_pooled * (1- p_hat_pooled) * (1/ n +1/ n))z = (p_hat1 - p_hat2) / se_pooledp_value =2* stats.norm.cdf(-np.abs(z))print("p-value for the difference of two population proportions:", p_value)
p-value for the difference of two population proportions: [0.00526024]
17 On the Use of the Normal Approximation (Optional)
The central limit theorem tells us that the sample proportion is approximately normally distributed for large sample sizes. However, it does not tell us how large exactly the sample size must be. The goodness of the approximation depends on how the population distribution looks like. If the population distribution is very skewed, then the approximation may be poor. A common rule of thumb is that the sample size is large enough if np \geq 5 and n(1 - p) \geq 5.
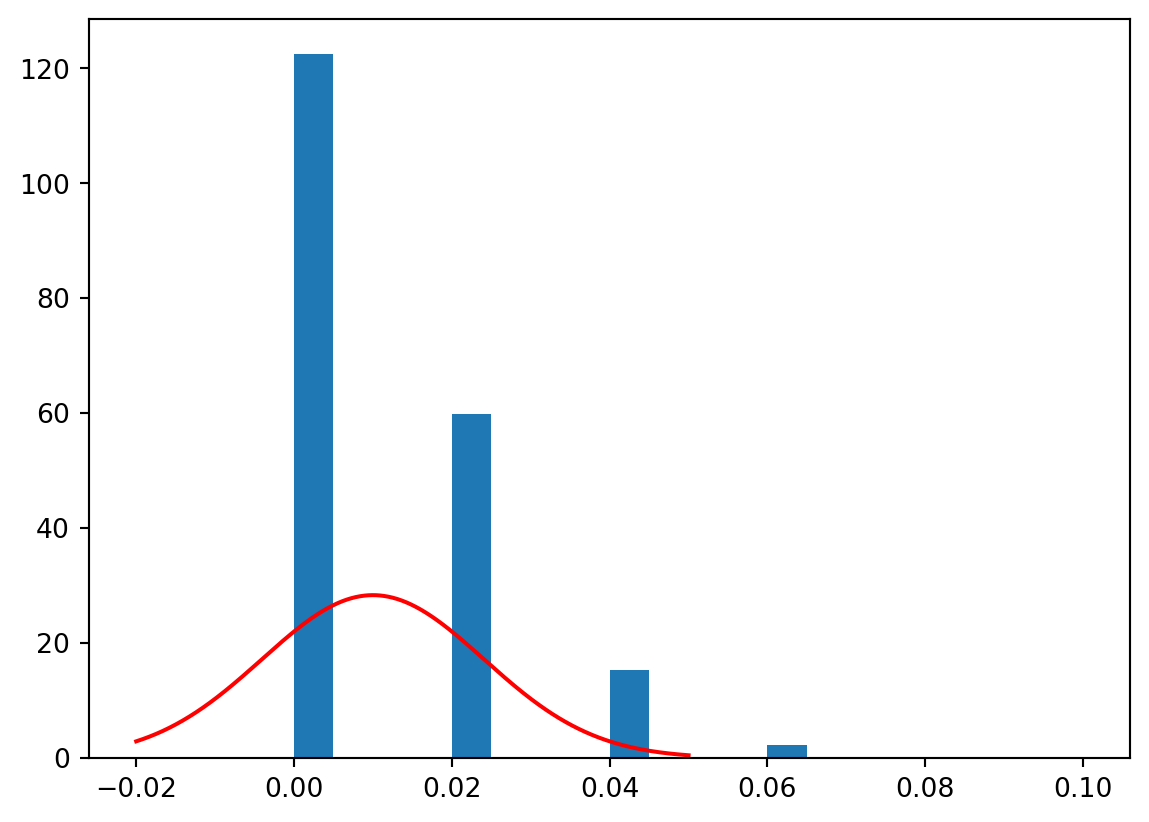
# The distribution of the sample proportion with a very skewed population proportionp =0.01n =50sample1000_skewed = np.random.binomial(n, p, size =10000)p_hat_skewed = sample1000_skewed / nse_skewed = np.sqrt(p_hat_skewed * (1- p_hat_skewed) / n)ci_025_skewed = p_hat_skewed - qn_975 * se_skewedci_975_skewed = p_hat_skewed - qn_025 * se_skewed# Plot the confidence intervals and the population proportion of successes for the first 50 samplesplt.errorbar(p_hat_skewed[0:show_samples], range(show_samples), xerr = qn_975 * se_skewed[0:show_samples], fmt ="o")plt.axvline(p, color ="red")plt.show()
# Plot the distribution of the sample proportion of successes# and overlay the normal approximationplt.hist(p_hat_skewed, bins =20, density=True)x = np.linspace(-0.02, 0.05, 1000)y = stats.norm.pdf(x, p, np.sqrt(p * (1- p) / n))plt.plot(x, y, color ="red")plt.show()
17.1 Tests for the Mean (Optional)
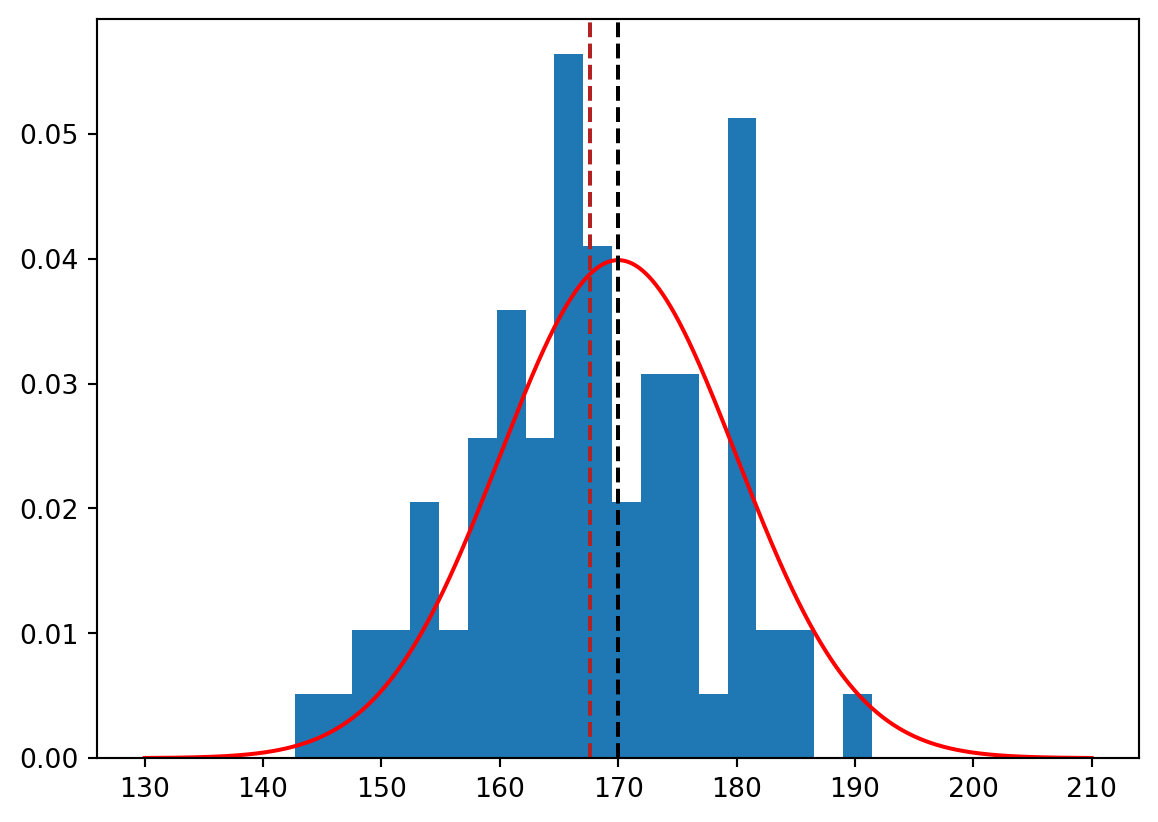
Very often we are interested in the average value of a random variable. Consider for example the average height of a population. We collect a sample of n = 80 persons, ask them for their height and calculate the average height of the sample. We can ask the question: is the average height of the sample consistent with the conjecture that the average height of the population greater than 170 cm? Let us assume that all observations are independent and that the height of a person is normally distributed with mean \mu and variance \sigma^2.
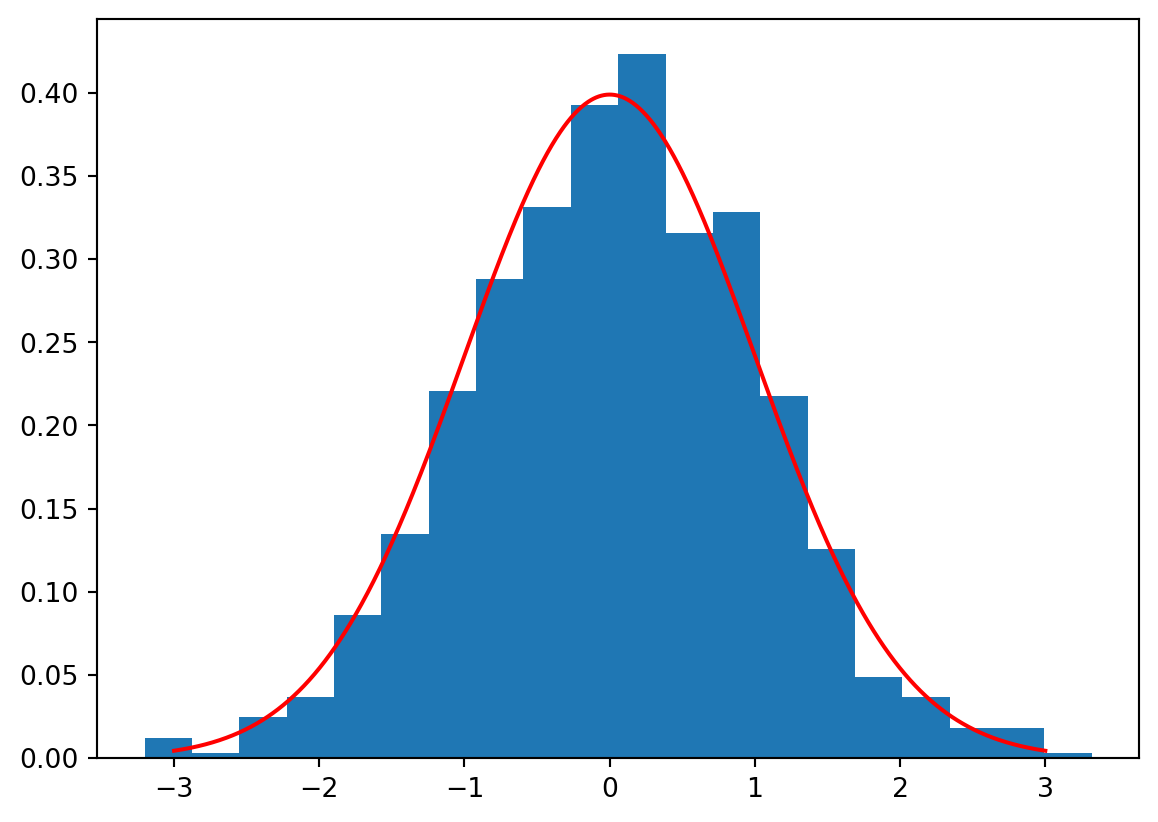
import matplotlib.pyplot as plt# Simulate 80 draws from a normal distribution with mean 170 and standard deviation 10n =80mu =170sigma =10sample100 = np.random.normal(mu, sigma, n)# Plot the histogram of the sample and overlay the density of the normal distributionplt.hist(sample100, bins =20, density =True)x = np.linspace(130, 210, 1000)y = stats.norm.pdf(x, mu, sigma)plt.plot(x, y, 'r')plt.axvline(x = mu, color ='black', linestyle ='--')plt.axvline(x = sample100.mean(), color ='firebrick', linestyle ='--')plt.show()
A summary of the data is a statistic that is called the z-statistic and it is defined as
z = \frac{\bar{X} - \mu_{H_{0}}}{\sigma/\sqrt{n}}
where \bar{X} is the average height of the sample. As the z-statistic is a function of the data (it depends on the sample mean \bar{X}), it is a random variable. If the null hypothesis is true, then the z-statistic is normally distributed with mean 0 and variance 1. The p-value of the test is the probability to observe a z-statistic less than or equal to the observed z-statistic. In Python, we can use the scipy.stats.norm module to calculate the cumulative distribution function of a normal random variable. The function norm.cdf calculates the cumulative distribution function of a normal random variable.
# Simulate 1000 samples of size 80 from a normal distribution with mean 170 and standard deviation 10n =80mu =170sigma =10R =1000samples = np.random.normal(mu, sigma, (R, n))# Calculate the z-statistic for each samplez = (samples.mean(axis =1) - mu) / (sigma / np.sqrt(n))# Plot the histogram of the z-statistics and overlay the density of the standard normal distributionplt.hist(z, bins =20, density =True)x = np.linspace(-3, 3, 1000)y = stats.norm.pdf(x, 0, 1)plt.plot(x, y, 'r')plt.show()
What you see in the graphic above is called the distribution of the z-statistic under the null hypothesis (i.e. assuming that it is true). We can use this distribution much in the same way as we used the binomial distribution in the previous example. Small values of the z-statistic are surprising if the null hypothesis is true and we can reject the null hypothesis if the p-value is less than 0.05.
# z-statistic for the samplez = (sample100.mean() - mu) / (sigma / np.sqrt(n))print("z-statistic for the sample:", z)# p-value for the z-statisticp_value = stats.norm.cdf(z)p_value
z-statistic for the sample: -2.1211560858308345
0.016954334708739513
The probability to observe a z-statistic less than or equal to the one computed in the sample is about 0.81. This is a large p-value, so we cannot reject the null hypothesis that the average height of the population is at least 170 cm. Now, this is not surprising, because we have taken the sample from a normal distribution with mean 170 cm. Let us now see how the distribution of the z-statistic looks like if the null hypothesis is false. We can do this by simulating the distribution of the z-statistic under the alternative hypothesis.
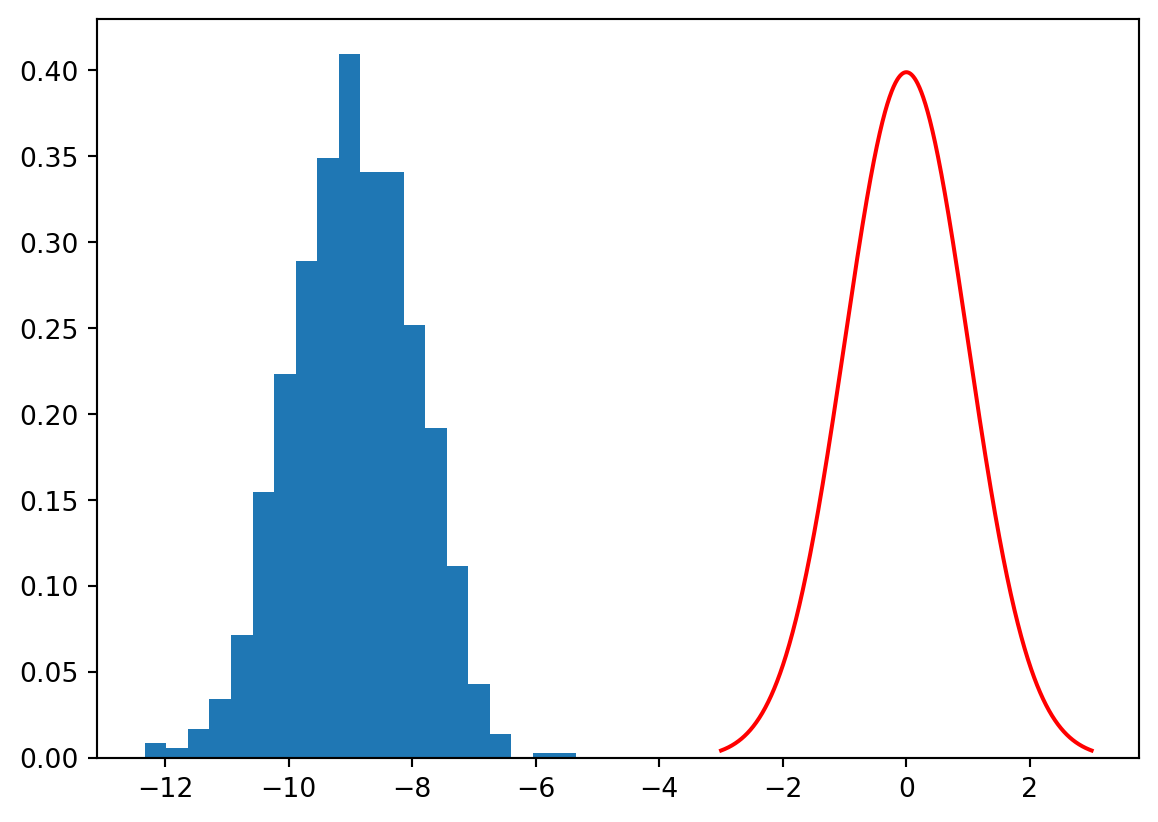
# Generate 1000 samples of size 80 from a normal distribution with mean 160 (a value from the alvernative) and standard deviation 10n =80mu =160sigma =10R =1000samples = np.random.normal(mu, sigma, (R, n))# Calculate the z-statistic for each samplez = (samples.mean(axis =1) -170) / (sigma / np.sqrt(n))# Plot the histogram of the z-statistics and overlay the density of the standard normal distributionplt.hist(z, bins =20, density =True)x = np.linspace(-3, 3, 1000)y = stats.norm.pdf(x, 0, 1)plt.plot(x, y, 'r')plt.show()
What you should see in this simulation is that the distribution of the z-statistic is shifted to the left and is not the same as the distribution of the z-statistic under the null hypothesis (the red density curve). This is because the average height of the population from wich we have taken the samples is 160 cm, not 170 as in the null hypothesis.
# Take a single sample of size 80 from a normal distribution with mean 160 and standard deviation 10, # calculate the z-statistic and compute its p-valuesample100 = np.random.normal(160, 10, n)z = (sample100.mean() -170) / (sigma / np.sqrt(n))p_value = stats.norm.cdf(z)p_value
1.55456300598205e-16
The p-value of the test is very small, so the data is extremely surprising. Here we reject the null hypothesis.
17.2 Some Notes about the p-value (Optional)
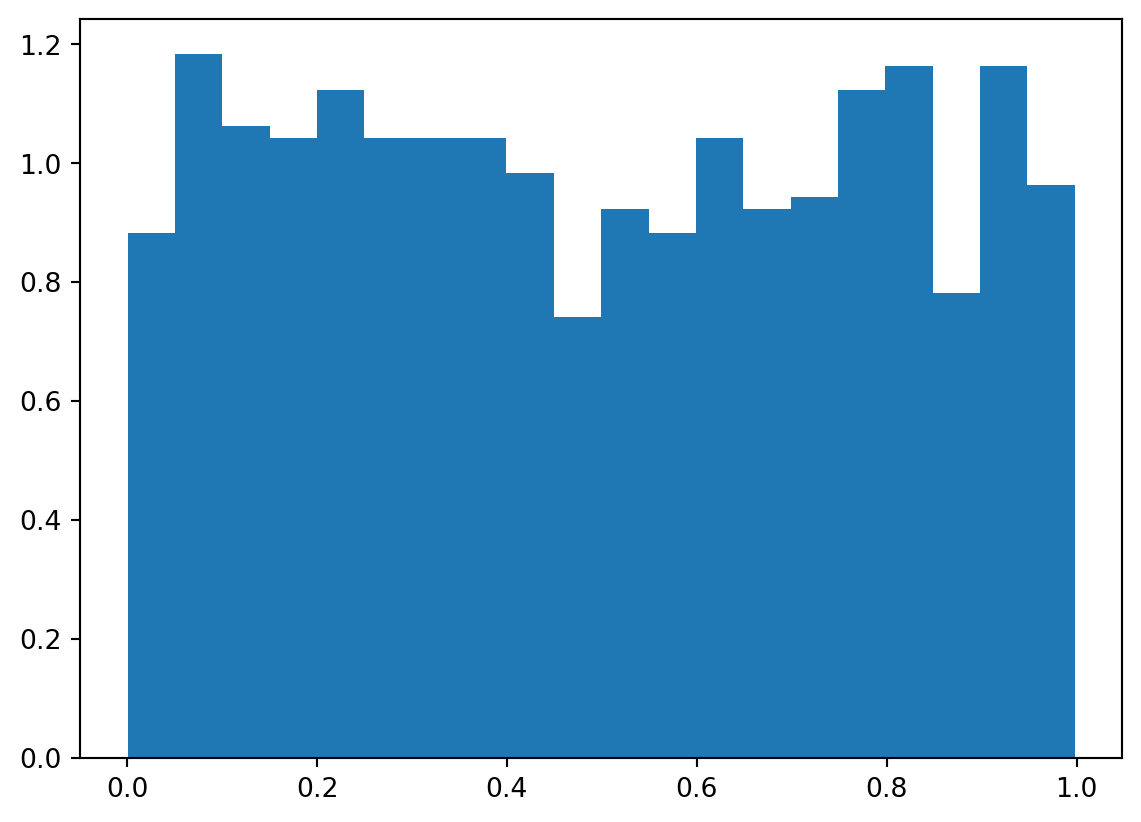
The p-value serves to reject or not to reject the null hypothesis. However, you should not consider it a measure of strength of evidence for the null hypothesis. As the p-value is calculated using the data, it itself is a random variable. It can be shown that under the null hypothesis it is uniformly distributed over the interval between 0 and 1. So, given a true null hypothesis, you would falsly reject it in 5% of the cases (different samples) if you follow the rule to reject for a p-value less than 0.05.
# Generate 1000 samples of size 80 from a normal distribution with mean 170 and standard deviation 10n =80mu =170sigma =10R =1000samples = np.random.normal(mu, sigma, (R, n))# Calculate the z-statistic for each samplez = (samples.mean(axis =1) -170) / (sigma / np.sqrt(n))# Calculate the p-value for each z-statisticp_values = stats.norm.cdf(z)# Count the number of p-values less than 0.05print("Number of p-values less than 0.05:", np.sum(p_values <0.05))# Calculate the proportion of p-values less than 0.05print("Proportion of p-values less than 0.05:", np.mean(p_values <0.05))# Show the histogram of the p-valuesplt.hist(p_values, bins =20, density =True)plt.show()
Number of p-values less than 0.05: 43
Proportion of p-values less than 0.05: 0.043
17.3 On the Construction of the z-statistic (Optional)
The z-statistic
z = \frac{\bar{X} - \mu_{H_0}}{\sigma/\sqrt{n}}
consists of two parts: the nominator and the denominator. If the null hypothesis is true, meaning that the sample was selected from a population with mean \mu_{H_0}, then we expect the nominator to be close to zero because of the law of large numbers. So one possibility for the nominator to be far away from zero (positive or negative) is that the null hypothesis is false. Another possibility to see a large z-statistic is simply by chance. Chance occurrences of large differences between the sample mean and the population mean are more likely if the sample size is small or if the population standard deviation is large. This is the role of the denominator. It scales the nominator by the standard deviation of the sample mean and thus decreases the z-statistic if the sample size is small or the population standard deviation is large.
# Generate 1000 sample for each combination of n and sigman_values = [10, 40, 80]sigma_values = [5, 20, 40]R =1000for i, n inenumerate(n_values):for j, sigma inenumerate(sigma_values): samples = np.random.normal(170, sigma, (R, n)) z_values_nominator = (samples.mean(axis =1) -170) z_values = z_values_nominator / (sigma / np.sqrt(n))print("n =", n, "sigma =", sigma, "Percentage of z-value nominators greater than 2 in absolute value:", 100* np.mean(np.abs(z_values_nominator) >2))print("n =", n, "sigma =", sigma, "Percentage of z-values graeter than 2 in absolute value:", 100* np.mean(np.abs(z_values) >2))
n = 10 sigma = 5 Percentage of z-value nominators greater than 2 in absolute value: 20.4
n = 10 sigma = 5 Percentage of z-values graeter than 2 in absolute value: 4.3
n = 10 sigma = 20 Percentage of z-value nominators greater than 2 in absolute value: 74.1
n = 10 sigma = 20 Percentage of z-values graeter than 2 in absolute value: 5.5
n = 10 sigma = 40 Percentage of z-value nominators greater than 2 in absolute value: 86.2
n = 10 sigma = 40 Percentage of z-values graeter than 2 in absolute value: 3.6999999999999997
n = 40 sigma = 5 Percentage of z-value nominators greater than 2 in absolute value: 0.8
n = 40 sigma = 5 Percentage of z-values graeter than 2 in absolute value: 4.1000000000000005
n = 40 sigma = 20 Percentage of z-value nominators greater than 2 in absolute value: 53.6
n = 40 sigma = 20 Percentage of z-values graeter than 2 in absolute value: 4.2
n = 40 sigma = 40 Percentage of z-value nominators greater than 2 in absolute value: 74.6
n = 40 sigma = 40 Percentage of z-values graeter than 2 in absolute value: 5.1
n = 80 sigma = 5 Percentage of z-value nominators greater than 2 in absolute value: 0.0
n = 80 sigma = 5 Percentage of z-values graeter than 2 in absolute value: 5.4
n = 80 sigma = 20 Percentage of z-value nominators greater than 2 in absolute value: 36.199999999999996
n = 80 sigma = 20 Percentage of z-values graeter than 2 in absolute value: 4.5
n = 80 sigma = 40 Percentage of z-value nominators greater than 2 in absolute value: 63.1
n = 80 sigma = 40 Percentage of z-values graeter than 2 in absolute value: 5.0
17.4 Test for the Mean with Unknown Variance (Optional)
In most settings the population variance \sigma^2 is unknown and needs to be estiamted from the sample. In this case, we can plug in the sample variance S^2 in place of the population variance. The resulting statistic is called the t-statistic and is defined as
t = \frac{\bar{X} - \mu}{S_x/\sqrt{n}}
where S_x is the sample standard deviation of X. The t-statistic is not normally distributed, but follows a t-distribution with n - 1 degrees of freedom (n is the number of observations in the sample). The p-value of the test is the probability to observe a t-statistic less than or equal to the observed t-statistic. In Python, we can use the scipy.stats.t module to calculate the cumulative distribution function of a t-distributed random variable. The function t.cdf calculates the cumulative distribution function of a t-distributed random variable.
The t-distribution is similar to the normal distribution, but has heavier tails. The heavier tails are a result of the fact that the sample standard deviation is an estimate of the population standard deviation and it is not perfect. The heavier tails mean that the t-distribution is more robust to violations of the assumption of normality. The t-distribution approaches the normal distribution as the sample size increases.
Let us consider the following example. We have collected a sample of 30 observations and we have calculated the sample mean (165 cm) and the sample standard deviation (15.0 cm). We want to test the null hypothesis that the average value of the population is at least 170. The null hypothesis is
\begin{align*}
t = \frac{165 - 170}{10/\sqrt{30}}
\end{align*}
Negative values of the t-statistic are evidence against the null hypothesis. The p-value of the test is the probability to observe a t-statistic less than or equal to the observed t-statistic. The p-value of the test is about 0.0001, so we reject the null hypothesis that the average value of the population is at least 170 cm.
t_stat = (165-170) / (15/ np.sqrt(30))print("t-statistic for the sample:", t_stat)print("p-value for the t-statistic:", stats.t.cdf(t_stat, 80-1))
t-statistic for the sample: -1.8257418583505538
p-value for the t-statistic: 0.0358339564821397
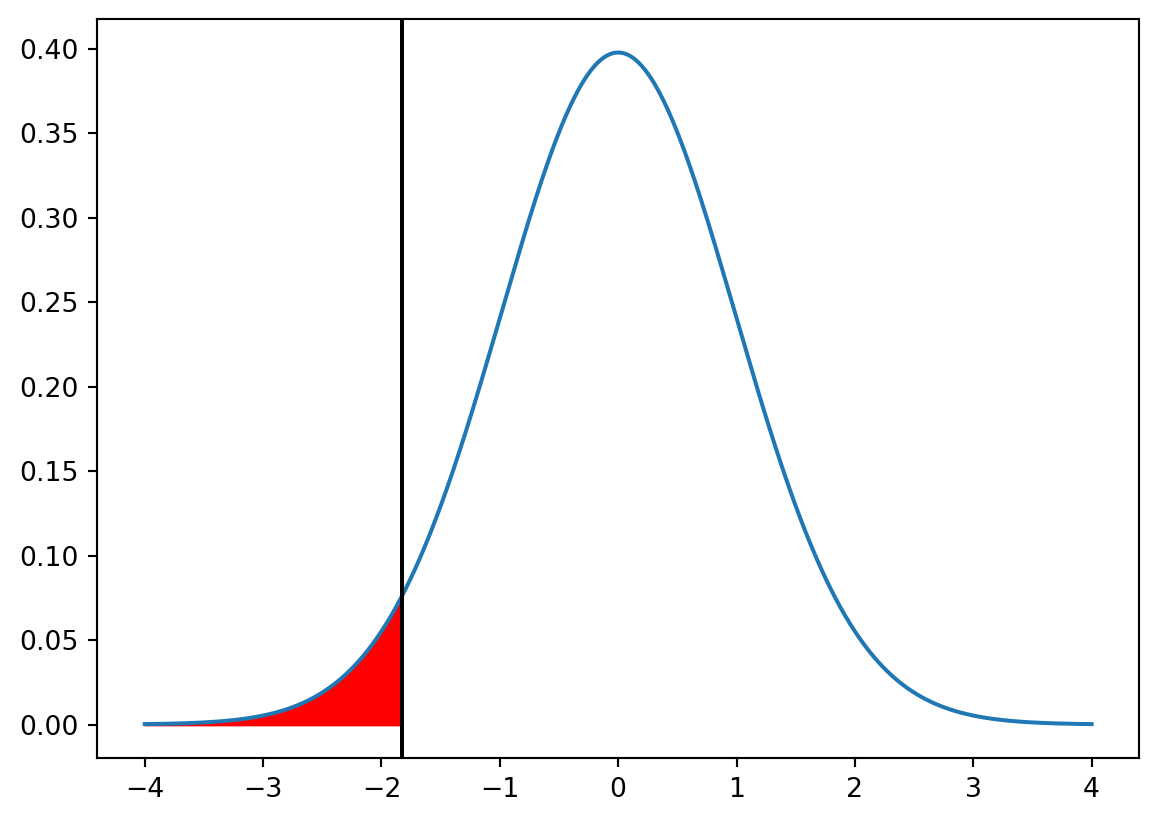
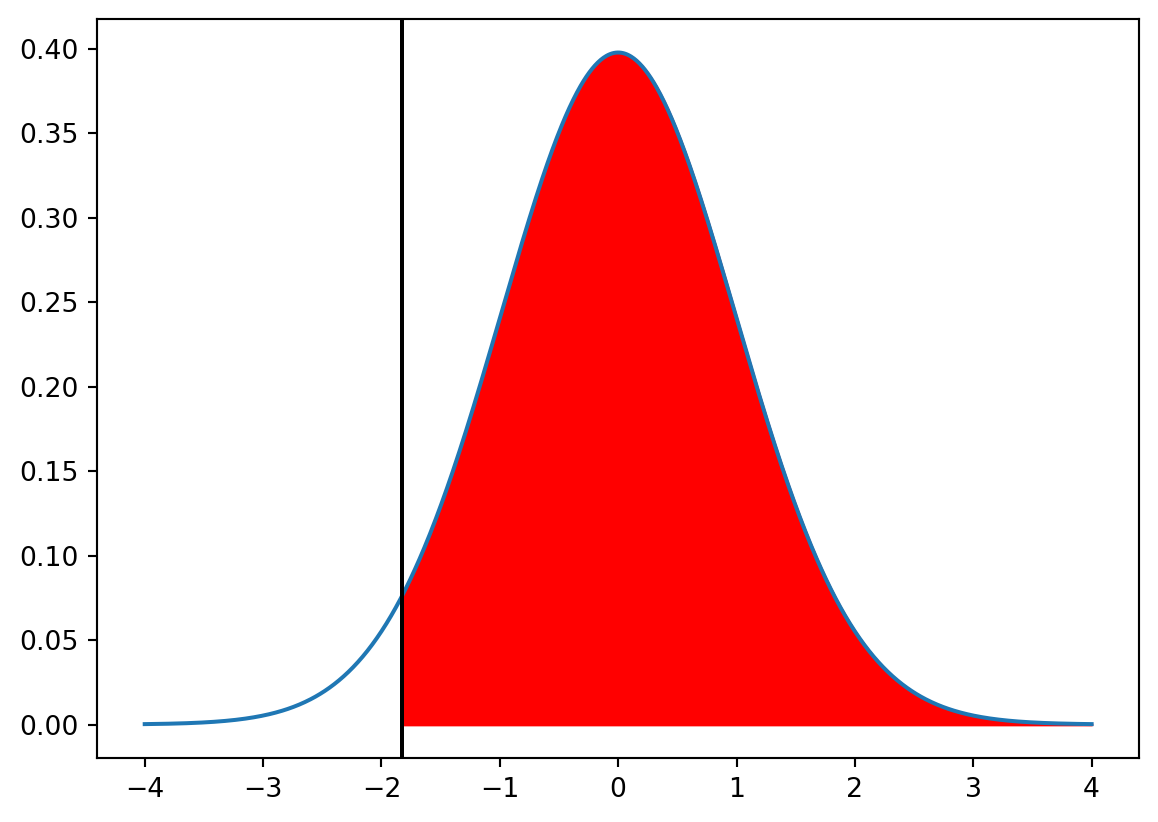
# Illustrate the p-value of the t-test as the area under the t-distributionx = np.linspace(-4, 4, 1000)y = stats.t.pdf(x, 80-1)plt.plot(x, y)plt.fill_between(x, y, where = x < t_stat, color ="red")plt.axvline(t_stat, color ="black")plt.show()
As the p-value of the test is less than 0.05 we will reject the null hypothesis at the 0.05 significance level.
The value of the t-statistic is the same as before, but the p-value is different. This time positive values of the t-statistic are evidence against the null hypothesis, so the p-value is the probability of observing a t-statistic greater than or equal to the observed t-statistic.
print("p-value for the t-statistic:", 1- stats.t.cdf(t_stat, 80-1))
p-value for the t-statistic: 0.9641660435178603
# Illustrate the p-value of the t-test as the area under the t-distributionx = np.linspace(-4, 4, 1000)y = stats.t.pdf(x, 80-1)plt.plot(x, y)plt.fill_between(x, y, where = x > t_stat, color ="red")plt.axvline(t_stat, color ="black")plt.show()
The p-value here is larger than 0.05, so we cannot reject the null hypothesis that the average value of the population is at most 170 cm.
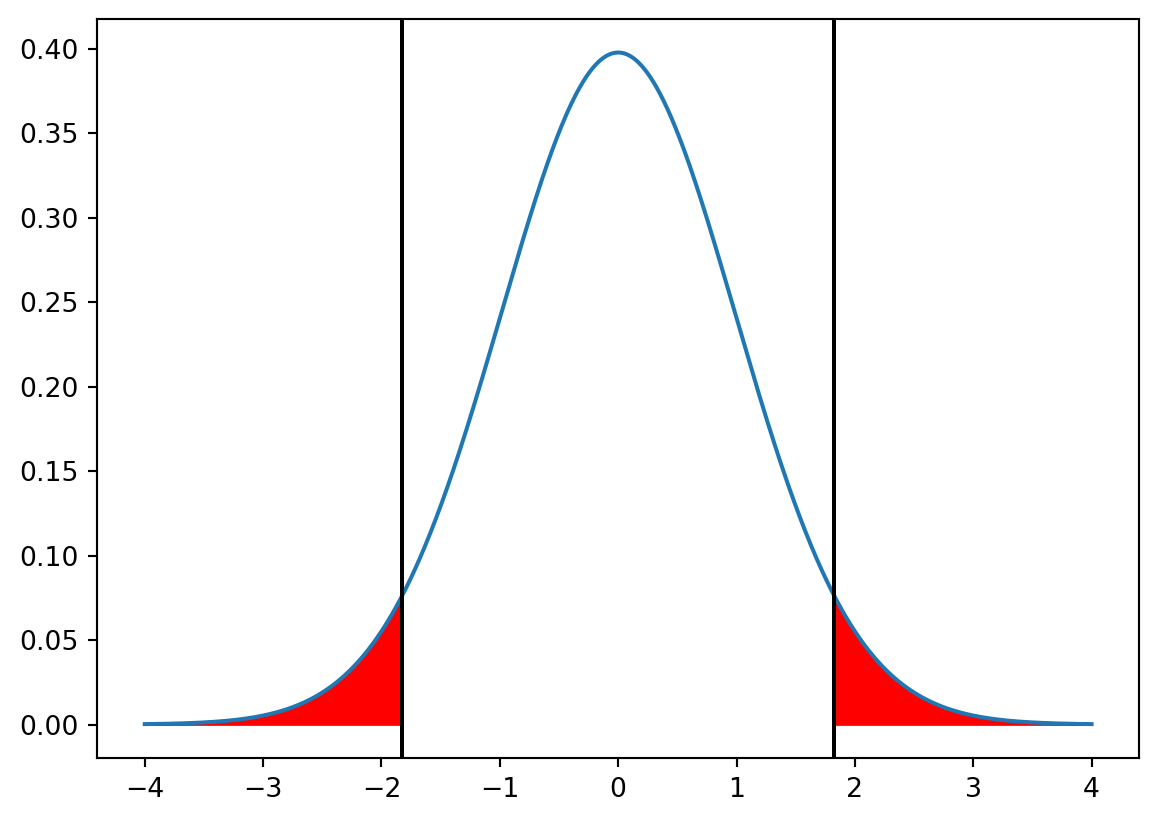
The value of the t-statistic in the sample is the same as before, but the calculation of the p-value is different, because both large positive and large negative values of the t-statistic are evidence against the null hypothesis. The p-value is the probability of observing a t-statistic less than or equal to the observed t-statistic or greater than or equal to the negative of the observed t-statistic.
# Calculate the p-value for the t-testprint("p-value for the t-test:", 2* stats.t.cdf(-np.abs(t_stat), 80-1))
p-value for the t-test: 0.0716679129642794
# Illustrate the p-value of the t-test as the area under the t-distributionx = np.linspace(-4, 4, 1000)y = stats.t.pdf(x, 80-1)plt.plot(x, y)plt.fill_between(x, y, where = (x <-np.abs(t_stat)) | (x > np.abs(t_stat)), color ="red")plt.axvline(t_stat, color ="black")plt.axvline(-t_stat, color ="black")plt.show()