Until now we have been dealing with univariate distributions, i.e., distributions of a single random variable. In this notebook, we will discuss bi-variate distributions, i.e., distributions of two random variables. We will start with the simplest case, the joint distribution of two discrete random variables.
10.1 Joint Distribution
Until now we have discussed the probability mass function (pmf) of a single discrete random variable. It answers questions such as “What is the probability that the random variable takes the value x?”. It is very common that we are interested in more than out random variable. For example, we might conduct an experiment where we assign different marketing strategies to groups of customers and measure the number of products they buy. In that case we might be interested in the joint outcome of the marketing strategy and the number of products bought.
For discrete distributions with a limited number of outcomes, we can represent the joint distribution as a table. For example, consider the following table of two random variables X and Y. X can take the values 0, 1, 2, and 3, and Y can take the values 2, and 3. The cells of the table contain the probability that the random variables take the corresponding values.
import pandas as pdimport numpy as npimport matplotlib.pyplot as plt# Import a couple of csv files from githubpx = pd.read_csv("https://raw.githubusercontent.com/febse/data/main/econ/prob_review/px.csv")py = pd.read_csv("https://raw.githubusercontent.com/febse/data/main/econ/prob_review/py.csv")pxy = pd.read_csv("https://raw.githubusercontent.com/febse/data/main/econ/prob_review/pxy.csv")# Select specific columnspxy = pxy[['x', 'y', 'p']]pxy_table = pd.pivot_table(pxy, values='p', index='x', columns='y')pxy_table
y
2
3
x
0
0.241
0.009
1
0.089
0.006
2
0.229
0.043
3
0.201
0.182
So we can look up probabilities such as
P(X=0, Y=2) = 0.241
directly from the table. We will write the PMF of two random variables X and Y as
f_{XY}(x, y) = P_{XY}(X=x, Y=y)
.
As the PMF of a single random variable, the joint PMF must satisfy the following properties:
f_{XY}(x, y) \geq 0 for all x and y.
\sum_x \sum_y f_{XY}(x, y) = 1.
# Verify that the sum of all probabilities is 1pxy_table.sum().sum()
1.0
11 Marginal Distributions
If we have a joint distribution of two random variables, we can calculate the marginal distribution of each of the random variables, which are simply the univariate distributions of each of the random variables. For example, the marginal distribution of X is
f_X(x) = \sum_y f_{XY}(x, y)
and the marginal distribution of Y is
f_Y(y) = \sum_x f_{XY}(x, y)
# The marginal distribution of y is the sum of the rows of the tablepxy_table.sum(axis=0)
y
2 0.76
3 0.24
dtype: float64
# The marginal distribution of x is the sum of the columns of the tablepxy_table.sum(axis=1)
x
0 0.250
1 0.095
2 0.272
3 0.383
dtype: float64
11.1 Conditional Distributions
A lot of questions in applied research boil down to the comparisons of conditional probabilities. For example, we might be interested in the probability that a customer buys a product given that they have been exposed to a certain marketing strategy or that a patient survives a decease given that they have been treated with a certain drug.
To be able to answer these questions, we need to calculate the conditional distribution of one random variable given the other. The conditional distribution of X given Y is defined as
# Conditional distribution of x given yx_marginal = pxy_table.sum(axis=0)print(x_marginal)px_given_y = pxy_table.div(x_marginal, axis=1)px_given_y
y
2 0.76
3 0.24
dtype: float64
y
2
3
x
0
0.317105
0.037500
1
0.117105
0.025000
2
0.301316
0.179167
3
0.264474
0.758333
# Conditional distribution of y given xy_marginal = pxy_table.sum(axis=1)print(y_marginal)py_given_x = pxy_table.div(y_marginal, axis=0)py_given_x
x
0 0.250
1 0.095
2 0.272
3 0.383
dtype: float64
y
2
3
x
0
0.964000
0.036000
1
0.936842
0.063158
2
0.841912
0.158088
3
0.524804
0.475196
11.2 Conditional Moments
The conditional distributions are probability distributions in their own right, and we can summarize them in the same way as we summarize univariate distributions. For example, we can calculate the conditional mean of X given Y as
E(X|Y=y) = \sum_x x f_{X|Y}(x|y)
and the conditional variance of X given Y as
Var(X|Y=y) = \sum_x (x - E(X|Y=y))^2 f_{X|Y}(x|y)
The Conditional Expectation is a Random Variable
Unlike the unconditional expectation, which is just a real number (not random), the conditional expectation depends on the value of the conditioning variable. Therefore, the conditional expectation is a random variable itself. This is important to keep in mind when we use the conditional expectation in further calculations.
The Expectation of the Joint Distribution is a Vector
The expectation of the joint distribution is a vector of the expectations of the individual random variables. For example, the expectation of the joint distribution of X and Y is
# In pandas it is easier to calculate the conditional moments in a long format (more rows than columns)pxy_long = pxy.melt(id_vars=['x', 'y'], var_name='var').rename(columns={'value': 'p'})pxy_long
x
y
var
p
0
0
2
p
0.241
1
0
3
p
0.009
2
1
2
p
0.089
3
1
3
p
0.006
4
2
2
p
0.229
5
2
3
p
0.043
6
3
2
p
0.201
7
3
3
p
0.182
# Conditional expectation of y given xpxy_long.groupby('x').apply(lambda d: (d['y'] * d['p'] / d['p'].sum()).sum())
/tmp/ipykernel_4650/1029770212.py:3: DeprecationWarning: DataFrameGroupBy.apply operated on the grouping columns. This behavior is deprecated, and in a future version of pandas the grouping columns will be excluded from the operation. Either pass `include_groups=False` to exclude the groupings or explicitly select the grouping columns after groupby to silence this warning.
pxy_long.groupby('x').apply(lambda d: (d['y'] * d['p'] / d['p'].sum()).sum())
# Conditional expectation of x given ypxy_long.groupby('y').apply(lambda d: (d['x'] * d['p'] / d['p'].sum()).sum())
/tmp/ipykernel_4650/2853574574.py:3: DeprecationWarning: DataFrameGroupBy.apply operated on the grouping columns. This behavior is deprecated, and in a future version of pandas the grouping columns will be excluded from the operation. Either pass `include_groups=False` to exclude the groupings or explicitly select the grouping columns after groupby to silence this warning.
pxy_long.groupby('y').apply(lambda d: (d['x'] * d['p'] / d['p'].sum()).sum())
y
2 1.513158
3 2.658333
dtype: float64
11.3 Covariance and Correlation
When we have two random variables, we are often interested in the relationship between them. For example, we may want to know how our product sales are related to marketing spending or how a person’s annual income is related to their education level (as measured by years spent in education, for example).
Here we will discuss a basic statistic that captures a linear relationship between two random variables, the covariance.
It is easier to understand the covariance if we start with its empirical counterpart, the sample covariance. The sample covariance between two random variables X and Y is defined as the average of the product of the deviations of the observations from their respective means. Let’s say we have n observations on pairs of values of X and Y, (x_1, y_1), (x_2, y_2), \ldots, (x_n, y_n). The sample covariance is then
# Let's do this with numpyx = np.array([0, 1, -1])y = np.array([2, 5, 0])x_mean = np.mean(x)y_mean = np.mean(y)print("Sample mean of x:", x_mean)print("Sample mean of y:", y_mean)
Sample mean of x: 0.0
Sample mean of y: 2.3333333333333335
# Now, compute the deviations of x from their meanx_dev = x - x_meanprint(x_dev)y_dev = y - y_meanprint(y_dev)
[ 0. 1. -1.]
[-0.33333333 2.66666667 -2.33333333]
# Now we have all the ingredients to compute the covarianceproducts = x_dev * y_devprint(products)cov_xy = np.sum(products) / (len(x) -1)print("Covariance of x and y:", cov_xy)
[-0. 2.66666667 2.33333333]
Covariance of x and y: 2.5
Now that you are familiar with the basic mechanics of the sample variance, let’s move on to understand what it captures. For this purpose, we will generate some random data and calculate the covariance.
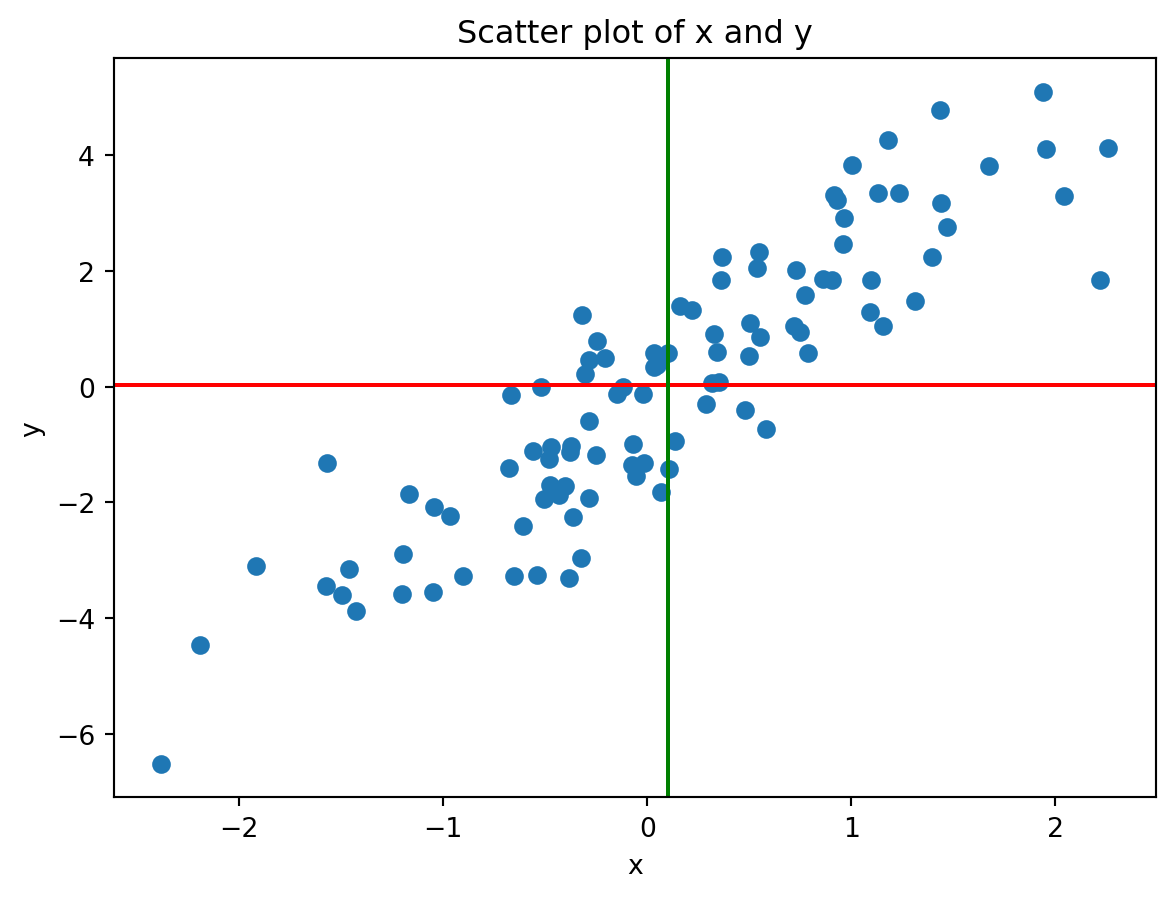
# Generate some data (positive linear relationship)x1 = np.random.randn(100)y1 =2* x1 + np.random.randn(100)print("Sample mean of x:", np.mean(x1))print("Sample mean of y:", np.mean(y1))print("Covariance matrix of x and y:\n", np.cov(x1, y1))# Plot plt.scatter(x1, y1)plt.axhline(y = np.mean(y1), color='red')plt.axvline(x = np.mean(x1), color='green')plt.xlabel('x')plt.ylabel('y')plt.title('Scatter plot of x and y')
Sample mean of x: 0.10176141532782532
Sample mean of y: 0.023289414202384756
Covariance matrix of x and y:
[[0.93110167 2.03452229]
[2.03452229 5.57012406]]
Text(0.5, 1.0, 'Scatter plot of x and y')
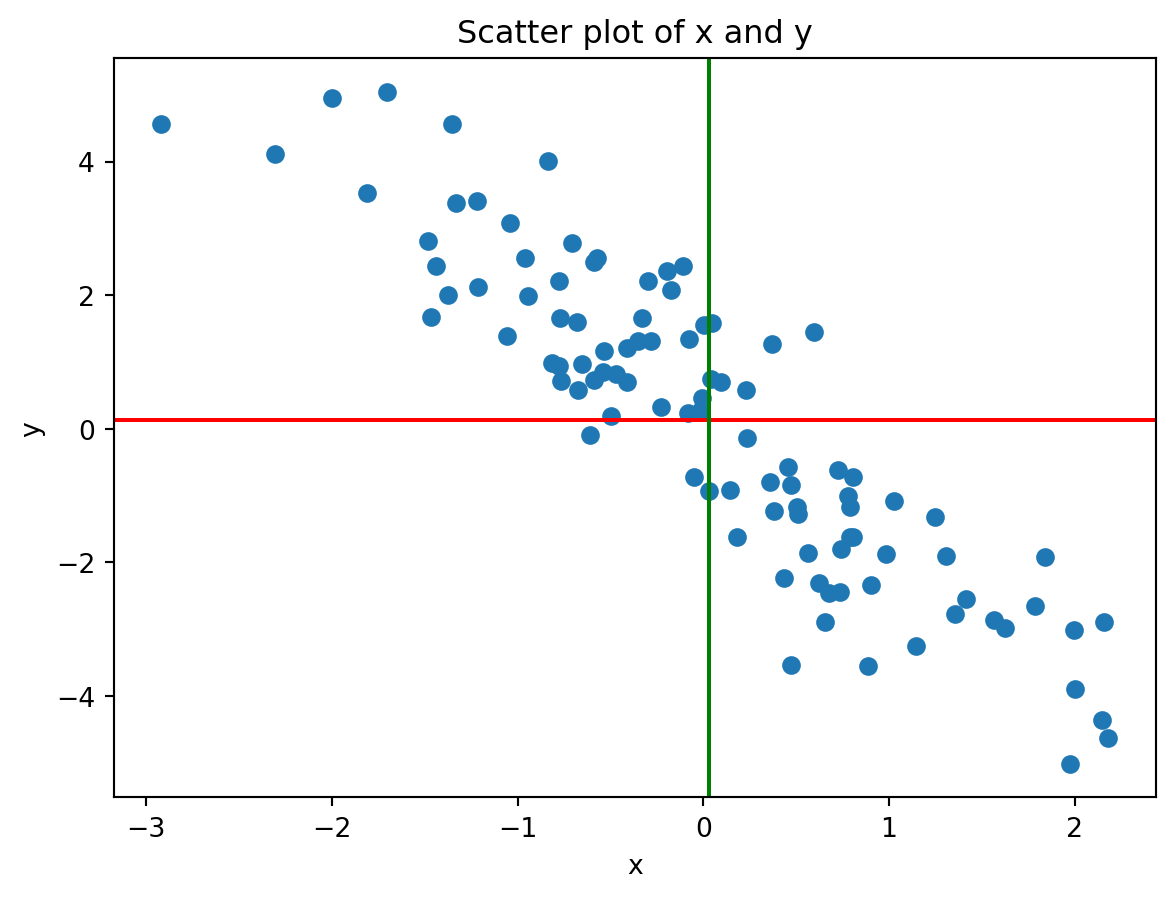
# Generate some data (negative linear relationship)x2 = np.random.randn(100)y2 =-2* x2 + np.random.randn(100)print("Sample mean of x:", np.mean(x2))print("Sample mean of y:", np.mean(y2))print("Covariance matrix of x and y:\n", np.cov(x2, y2))# Plotplt.scatter(x2, y2)plt.axhline(y = np.mean(y2), color='red')plt.axvline(x = np.mean(x2), color='green')plt.xlabel('x')plt.ylabel('y')plt.title('Scatter plot of x and y')
Sample mean of x: 0.03316982225000491
Sample mean of y: 0.1305293586079987
Covariance matrix of x and y:
[[ 1.11140176 -2.2034982 ]
[-2.2034982 5.38691243]]
Text(0.5, 1.0, 'Scatter plot of x and y')
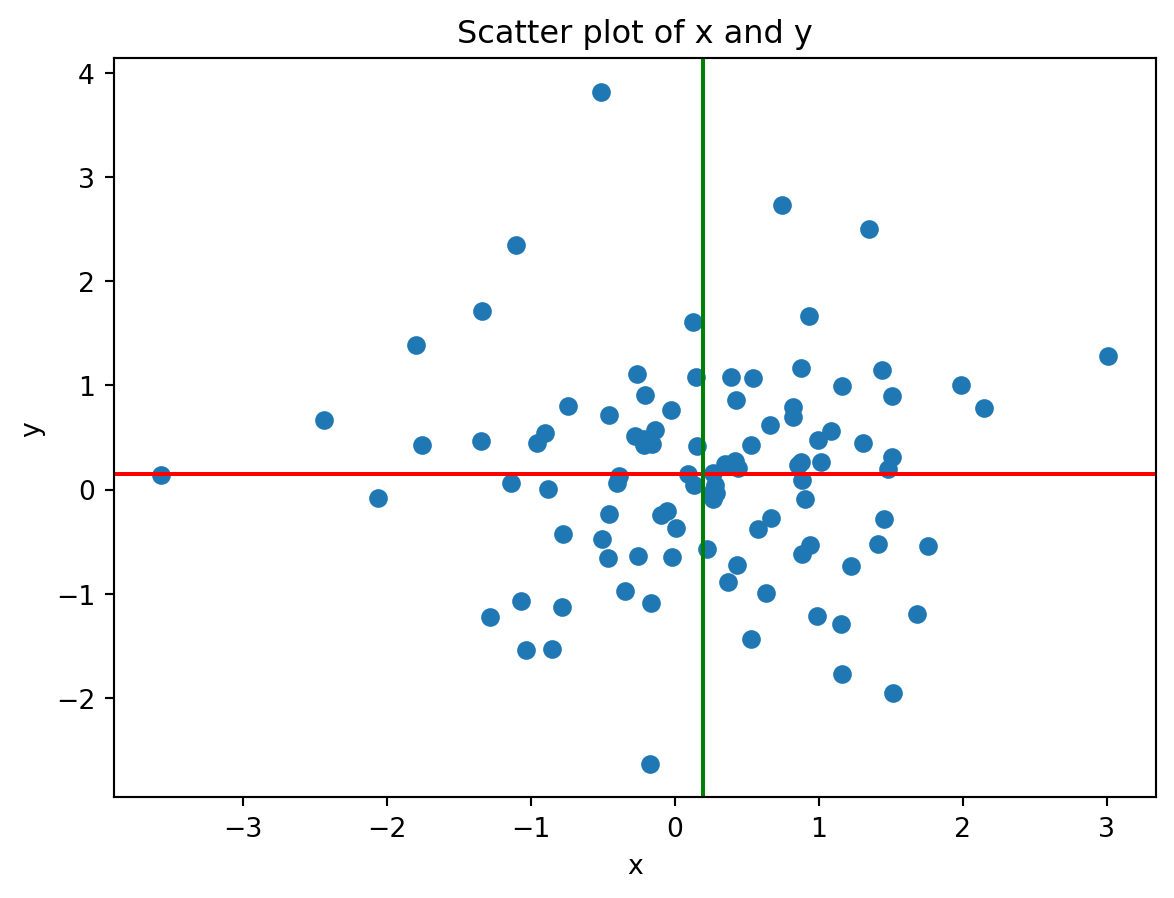
# Generate some data (no linear relationship)x3 = np.random.randn(100)y3 = np.random.randn(100)print("Sample mean of x:", np.mean(x3))print("Sample mean of y:", np.mean(y3))print("Covariance matrix of x and y:\n", np.cov(x3, y3))# Plotplt.scatter(x3, y3)plt.axhline(y = np.mean(y3), color='red')plt.axvline(x = np.mean(x3), color='green')plt.xlabel('x')plt.ylabel('y')plt.title('Scatter plot of x and y')
Sample mean of x: 0.19379131938667896
Sample mean of y: 0.14522228953680372
Covariance matrix of x and y:
[[1.07952495 0.00725404]
[0.00725404 1.02424869]]
Text(0.5, 1.0, 'Scatter plot of x and y')
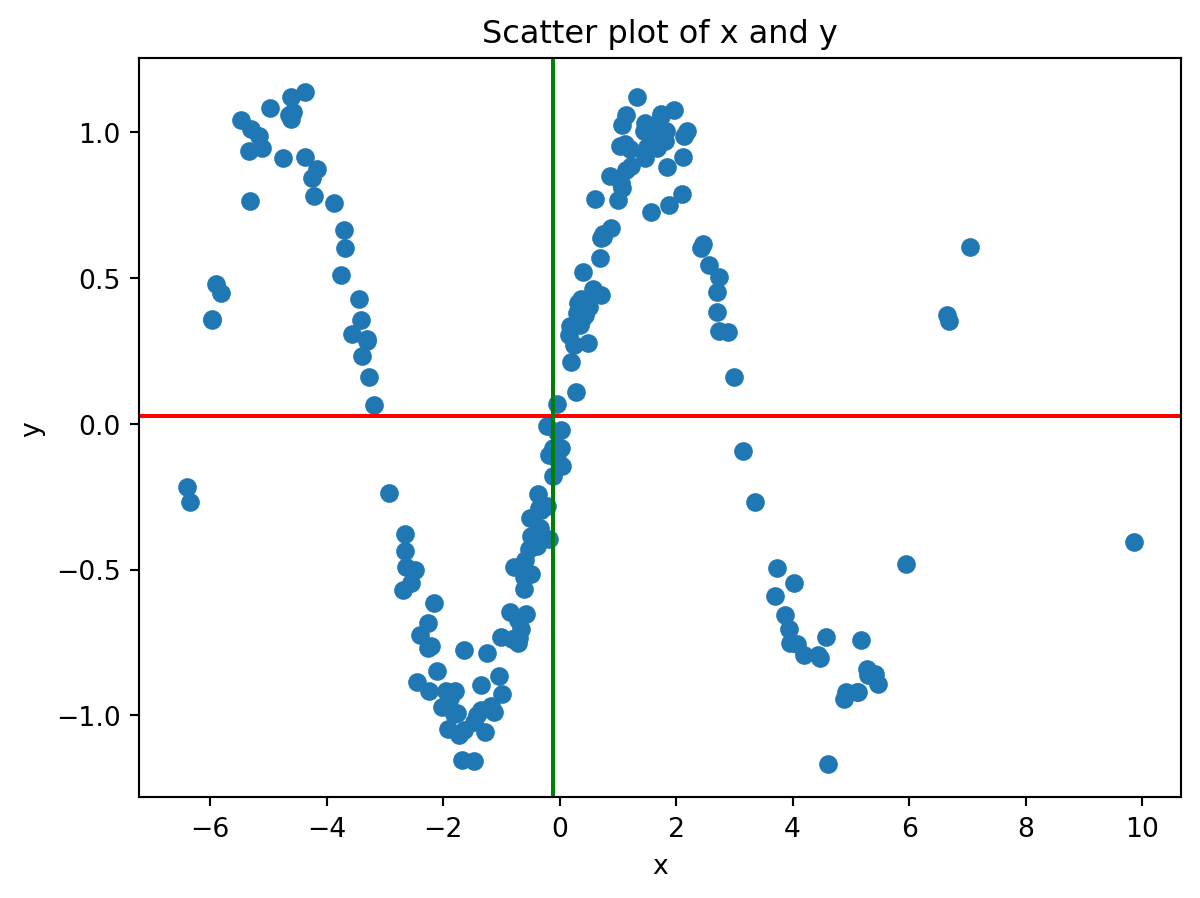
11.4 Non-Linear Relationships
It is important to remember that the covariance only captures linear relationships between two random variables. If the relationship is non-linear, the covariance will still describe the linear relationship between the two variables. However, it may be close to zero even if there is a strong non-linear relationship between the two variables.
# Generate some data (quadratic relationship)x4 = np.random.randn(200) *3y4 = np.sin(x4) + np.random.randn(200) *0.1print("Sample mean of x:", np.mean(x4))print("Sample mean of y:", np.mean(y4))print("Covariance matrix of x and y:\n", np.cov(x4, y4))# Plotplt.scatter(x4, y4)plt.axhline(y = np.mean(y4), color='red')plt.axvline(x = np.mean(x4), color='green')plt.xlabel('x')plt.ylabel('y')plt.title('Scatter plot of x and y')
Sample mean of x: -0.11581347212625419
Sample mean of y: 0.02839863933990328
Covariance matrix of x and y:
[[ 9.05862826 -0.26170163]
[-0.26170163 0.52738521]]
Text(0.5, 1.0, 'Scatter plot of x and y')
11.5 Correlation
The sign of the covariance tells us about the direction of the relationship between two random variables. If the covariance is positive, the two variables tend to move in the same direction. If the covariance is negative, the two variables tend to move in opposite directions. However, we cannot say anything about how strong the relationship is.
The reason is that the covariance depends on the scale of the variables. For example, let’s say we have two sets of measurements: height in m and monthly salary in 1000 USD.
# Now let's change the units of height to centimetersheight_cm = height_m *100np.cov(height_cm, income_1000USD)
array([[170.8 , 7.78 ],
[ 7.78 , 0.748]])
Notice that the covariance has changed and is now exactly 100 times larger than before. As an exercise, change the unit of measurement of the income to USD and see how the covariance changes.
11.6 Of Variability and Variance
Until now we have discussed the span of the data and the inter-quartile range as measures of variability. Another measure of variability is the variance.
Definition 11.1 (The Sample Variance and Sample Standard Deviation) The variance of a collection of n values x_1, x_2, \ldots, x_n is calculated as the average (with a correction factor) of the squared differences between each value and the mean:
The standard deviation is the square root of the variance:
\text{S}_{x} = \sqrt{\text{S}^2_{x}}
What are the units of measurement of the variance and the standard deviation?
Assume that x is measured in meters. What are the units of measurement of the variance and the standard deviation?
Assume that x is measured in centimeters. What are the units of measurement of the variance and the standard deviation?
Assume that x is measured in years. What are the units of measurement of the variance and the standard deviation?v
Example 11.1 (Computing the sample variance and the sample standard deviation) Given a set of measurements x = (x_1 = 1, x_2 = 8, x_3 = 3), calculate the sample variance and the sample standard deviation.
Until now we have discussed the sample covariance, which is a measure of the linear relationship between two sets of observations. The covariance of two random variables is a generalization of the sample covariance to random variables. The covariance of two random variables X and Y is defined as
\text{Cov}(X, Y) = E((X - E(X))(Y - E(Y)))
where E(X) and E(Y) are the expectations of X and Y, respectively. The covariance has the following properties:
\text{Cov}(X, Y) = \text{Cov}(Y, X)
\text{Cov}(X, X) = \text{Var}(X)
\text{Cov}(aX, bY) = ab \text{Cov}(X, Y)
\text{Cov}(X + Y, Z) = \text{Cov}(X, Z) + \text{Cov}(Y, Z)
11.8 The Correlation between Two Random Variables
The correlation between two random variables X and Y is defined as